This post was originally published on this site
This article was written, edited and designed on laptop computers. Such foldable, transportable devices would have astounded computer scientists just a few decades ago, and seemed like sheer magic before that. The machines contain billions of tiny computing elements, running millions of lines of software instructions, collectively written by countless people across the globe. You click or tap or type or speak, and the result seamlessly appears on the screen.
Computers were once so large they filled rooms. Now they’re everywhere and invisible, embedded in watches, car engines, cameras, televisions and toys. They manage electrical grids, analyze scientific data and predict the weather. The modern world would be impossible without them.
Scientists aim to make computers faster and programs more intelligent, while deploying technology in an ethical manner. Their efforts build on more than a century of innovation.
In 1833, English mathematician Charles Babbage conceived a programmable machine that presaged today’s computing architecture, featuring a “store” for holding numbers, a “mill” for operating on them, an instruction reader and a printer. This Analytical Engine also had logical functions like branching (if X, then Y). Babbage constructed only a piece of the machine, but based on its description, his acquaintance Ada Lovelace saw that the numbers it might manipulate could represent anything, even music. “A new, a vast, and a powerful language is developed for the future use of analysis,” she wrote. Lovelace became an expert in the proposed machine’s operation and is often called the first programmer.
To celebrate our 100th anniversary, we’re highlighting some of the biggest advances in science over the last century. To see more from the series, visit Century of Science.
In 1936, English mathematician Alan Turing introduced the idea of a computer that could rewrite its own instructions, making it endlessly programmable. His mathematical abstraction could, using a small vocabulary of operations, mimic a machine of any complexity, earning it the name “universal Turing machine.”
The first reliable electronic digital computer, Colossus, was completed in 1943 to help England decipher wartime codes. It used vacuum tubes — devices for controlling the flow of electrons — instead of moving mechanical parts like the Analytical Engine’s cogwheels. This made Colossus fast, but engineers had to manually rewire it every time they wanted to perform a new task.
Perhaps inspired by Turing’s concept of a more easily reprogrammable computer, the team that created the United States’ first electronic digital computer, ENIAC, drafted a new architecture for its successor, EDVAC. Mathematician John von Neumann, who penned EDVAC’s design in 1945, described a system that could store programs in its memory alongside data and alter the programs, a setup now called the von Neumann architecture. Nearly every computer today follows that paradigm.
In 1947, researchers at Bell Telephone Laboratories invented the transistor, a piece of circuitry in which the application of voltage (electrical pressure) or current controls the flow of electrons between two points. It came to replace the slower and less-efficient vacuum tubes.
In 1958 and 1959, researchers at Texas Instruments and Fairchild Semiconductor independently invented integrated circuits, in which transistors and their supporting circuitry were fabricated on a chip in one process.
For a long time, only experts could program computers. Then in 1957, IBM released FORTRAN, a programming language that was much easier to understand. It’s still in use today. In 1981, the company unveiled the IBM PC, and Microsoft released its operating system called MS-DOS, together expanding the reach of computers into homes and offices. Apple further personalized computing with the operating systems for their Lisa, in 1982, and Macintosh, in 1984. Both systems popularized graphical user interfaces, or GUIs, offering users a mouse cursor instead of a command line.

Meanwhile, researchers had been working to transform how people communicate with each other. In 1948, U.S. mathematician Claude Shannon published “A Mathematical Theory of Communication,” which popularized the word bit (for binary digit) and laid the foundation for information theory. His ideas have shaped computation and in particular the sharing of data over wires and through the air. In 1969, the U.S. Advanced Research Projects Agency created a computer network called ARPANET, which later merged with other networks to form the internet. And in 1990, researchers at CERN — a European laboratory near Geneva — developed rules for transmitting data that would become the foundation of the World Wide Web.
These technological advances have made it possible for people to work, play and connect in ways that continue to change at a dizzying pace. But how much better can the processors get? How smart can algorithms become? And what kinds of benefits and dangers should we expect to see as technology advances? Stuart Russell, a computer scientist at the University of California, Berkeley who coauthored a popular textbook on artificial intelligence, sees great potential for computers in “expanding artistic creativity, accelerating science, serving as diligent personal assistants, driving cars and — I hope — not killing us.”
Chasing speed
Computers, for the most part, speak the language of bits. They store information — whether it’s music, an application or a password — in strings of 1s and 0s. They also process information in a binary fashion, flipping transistors between an “on” and “off” state. The more transistors in a computer, the faster it can process bits, making possible everything from more realistic video games to safer air traffic control.
Combining transistors forms one of the building blocks of a circuit, called a logic gate. An AND logic gate, for example, is on if both inputs are on, while an OR is on if at least one input is on. Together, logic gates compose a complex traffic pattern of electrons, the physical manifestation of computation. A computer chip can contain millions of logic gates.
So the more logic gates, and by extension the more transistors, the more powerful the computer. In 1965, Gordon Moore, a cofounder of Fairchild Semiconductor and later of Intel, wrote a paper on the future of chips titled “Cramming More Components onto Integrated Circuits.” From 1959 to 1965, he noted, the number of components (mostly transistors) crammed onto integrated circuits (chips) had doubled every year. He expected the trend to continue.
In a 1975 talk, Moore identified three factors behind this exponential growth: smaller transistors, bigger chips and “device and circuit cleverness,” such as less wasted space. He expected the doubling to occur every two years. It did, and continued doing so for decades. That trend is now called Moore’s law.
Moore’s law was meant as an observation about economics. There will always be incentives to make computers faster and cheaper — but at some point, physics interferes. Chip development can’t keep up with Moore’s law forever, as it becomes more difficult to make transistors tinier. According to what’s jokingly called Moore’s second law, the cost of chip fabrication plants doubles every few years. The semiconductor company TSMC is reportedly considering building a plant that will cost $25 billion.
Today, Moore’s law no longer holds; doubling is happening at a slower rate. We continue to squeeze more transistors onto chips with each generation, but the generations come less frequently. Researchers are looking into several ways forward: better transistors, more specialized chips, new chip concepts and software hacks.
“We’ve squeezed, we believe, everything you can squeeze” out of the current transistor architecture, called FinFET, says Sanjay Natarajan, who leads transistor design at Intel. In the next few years, chip manufacturers will start producing transistors in which a key element resembles a ribbon instead of a fin, making devices faster and requiring less energy and space.
Even if Natarajan is right and transistors are nearing their minimum size limit, computers still have a lot of runway to improve, through Moore’s “device and circuit cleverness.” Today’s electronic devices contain many kinds of accelerators — chips designed for special purposes such as AI, graphics or communication — that can execute intended tasks faster and more efficiently than general-purpose processing units.
The slowdown
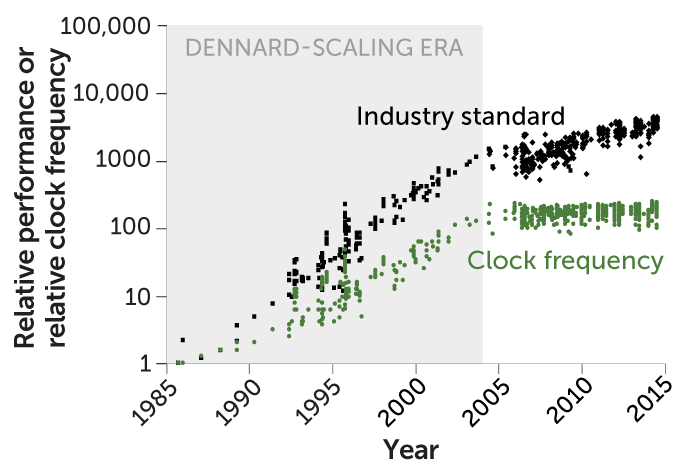
Until about 2004, the shrinking of transistors came with improvements in computer performance (black below shows an industry benchmark) and clock frequency — the number of cycles of operations performed per second (green). As this “Dennard scaling” no longer held, shrinking transistors stopped yielding the same benefits.
Computer performance from 1985 through 2015
Some types of accelerators might one day use quantum computing, which capitalizes on two features of the subatomic realm (SN: 7/8/17 & 7/22/17, p. 28). The first is superposition, in which particles can exist not just in one state or another, but in some combination of states until the state is explicitly measured. So a quantum system represents information not as bits but as qubits, which can preserve the possibility of being either 0 or 1 when measured. The second is entanglement, the interdependence between distant quantum elements. Together, these features mean that a system of qubits can represent and evaluate exponentially more possibilities than there are qubits — all combinations of 1s and 0s simultaneously.
Qubits can take many forms, but one of the most popular is as current in superconducting wires. These wires must be kept at a fraction of a degree above absolute zero, around –273° Celsius, to prevent hot, jiggling atoms from interfering with the qubits’ delicate superpositions and entanglement. Quantum computers also need many physical qubits to make up one “logical,” or effective, qubit, with the redundancy acting as error correction (SN: 11/6/21, p. 8).
Quantum computers have several potential applications: machine learning, optimization of things like train scheduling and simulating real-world quantum mechanics, as in chemistry. But they will not likely become general-purpose computers. It’s not clear how you’d use one to, say, run a word processor.
New chip concepts
There remain new ways to dramatically speed up not just specialized accelerators but also general-purpose chips. Tom Conte, a computer scientist at Georgia Tech in Atlanta who leads the IEEE Rebooting Computing Initiative, points to two paradigms. The first is superconduction, in which chips run at a temperature low enough to eliminate electrical resistance.
The second paradigm is reversible computing, in which bits are reused instead of expelled as heat. In 1961, IBM physicist Rolf Landauer merged information theory and thermodynamics, the physics of heat. He noted that when a logic gate takes in two bits and outputs one, it destroys a bit, expelling it as entropy, or randomness, in the form of heat. When billions of transistors operate at billions of cycles per second, the wasted heat adds up, and the machine needs more electricity for computing and cooling. Michael Frank, a computer scientist at Sandia National Laboratories in Albuquerque who works on reversible computing, wrote in 2017: “A conventional computer is, essentially, an expensive electric heater that happens to perform a small amount of computation as a side effect.”
But in reversible computing, logic gates have as many outputs as inputs. This means that if you ran the logic gate in reverse, you could use, say, three out-bits to obtain the three in-bits. Some researchers have conceived of reversible logic gates and circuits that could not only save those extra out-bits but also recycle them for other calculations. Physicist Richard Feynman had concluded that, aside from energy loss during data transmission, there’s no theoretical limit to computing efficiency.
Combine reversible and superconducting computing, Conte says, and “you get a double whammy.” Efficient computing allows you to run more operations on the same chip without worrying about power use or heat generation. Conte says that, eventually, one or both of these methods “probably will be the backbone of a lot of computing.”
Software hacks
Researchers continue to work on a cornucopia of new technologies for transistors, other computing elements, chip designs and hardware paradigms: photonics, spintronics, biomolecules, carbon nanotubes. But much more can still be eked out of current elements and architectures merely by optimizing code.
In a 2020 paper in Science, for instance, researchers studied the simple problem of multiplying two matrices, grids of numbers used in mathematics and machine learning. The calculation ran more than 60,000 times faster when the team picked an efficient programming language and optimized the code for the underlying hardware, compared with a standard piece of code in the Python language, which is considered user-friendly and easy to learn.
Neil Thompson, a research scientist at MIT who coauthored the paper in Science, recently coauthored a paper looking at historical improvements in algorithms, sets of instructions that make decisions according to rules set by humans, for tasks like sorting data. “For a substantial minority of algorithms,” he says, “their progress has been as fast or faster than Moore’s law.”
People, including Moore, have predicted the end of Moore’s law for decades. Progress may have slowed, but human innovation has kept technology moving at a fast clip.
Chasing intelligence
From the early days of computer science, researchers have aimed to replicate human thought. Alan Turing opened a 1950 paper titled “Computing Machinery and Intelligence” with: “I propose to consider the question, ‘Can machines think?’ ” He proceeded to outline a test, which he called “the imitation game” (now called the Turing test), in which a human communicating with a computer and another human via written questions had to judge which was which. If the judge failed, the computer could presumably think.
The term “artificial intelligence” was coined in a 1955 proposal for a summer institute at Dartmouth College. “An attempt will be made,” the proposal goes, “to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves.” The organizers expected that over two months, the 10 summit attendees would make a “significant advance.”
More than six decades and untold person-hours later, it’s unclear whether the advances live up to what was in mind at that summer summit. Artificial intelligence surrounds us in ways invisible (filtering spam), headline-worthy (self-driving cars, beating us at chess) and in between (letting us chat with our smartphones). But these are all narrow forms of AI, performing one or two tasks well. What Turing and others had in mind is called artificial general intelligence, or AGI. Depending on your definition, it’s a system that can do most of what humans do.

We may never achieve AGI, but the path has led, and will lead, to lots of useful innovations along the way. “I think we’ve made a lot of progress,” says Doina Precup, a computer scientist at McGill University in Montreal and head of the AI company DeepMind’s Montreal research team. “But one of the things that, to me, is still missing right now is more of an understanding of the principles that are fundamental in intelligence.”
AI has made great headway in the last decade, much of it due to machine learning. Previously, computers relied more heavily on symbolic AI, which uses algorithms based on human-set rules. Machine-learning programs, on the other hand, process data to find patterns on their own. One form uses artificial neural networks, software with layers of simple computing elements that together mimic certain principles of biological brains. Neural networks with several, or many more, layers are currently popular and make up a type of machine learning called deep learning.
Deep-learning systems can now play games like chess and Go better than the best human. They can probably identify dog breeds from photos better than you can. They can translate text from one language to another. They can control robots and compose music and predict how proteins will fold.
But they also lack much of what falls under the umbrella term of common sense. They don’t understand fundamental things about how the world works, physically or socially. Slightly changing images in a way that you or I might not notice, for example, can dramatically affect what a computer sees. Researchers found that placing a few innocuous stickers on a stop sign can lead software to interpret the sign as a speed limit sign, an obvious problem for self-driving cars.

Types of learning
How can AI improve? Computer scientists are leveraging multiple forms of machine learning, whether the learning is “deep” or not. One common form is called supervised learning, in which machine-learning systems, or models, are trained by being fed labeled data such as images of dogs and their breed names. But that requires lots of human effort to label them. Another approach is unsupervised or self-supervised learning, in which computers learn without relying on outside labels, the way you or I predict what a chair will look like from different angles as we walk around it.
Another type of machine learning is reinforcement learning, in which a model interacts with an environment, exploring sequences of actions to achieve a goal. Reinforcement learning has allowed AI to become an expert at board games like Go and video games like StarCraft II.
To learn efficiently, machines (and people) need to generalize, to draw abstract principles from experiences. “A huge part of intelligence,” says Melanie Mitchell, a computer scientist at the Santa Fe Institute in New Mexico, “is being able to take one’s knowledge and apply it in different situations.” Much of her work involves analogies, in rudimentary form: finding similarities between strings of letters. In 2019, AI researcher François Chollet of Google created a kind of IQ test for machines called the Abstraction and Reasoning Corpus, or ARC, in which computers must complete visual patterns according to principles demonstrated in example patterns. The puzzles are easy for humans, but so far, challenging for machines.
Much of our abstract thought, ironically, may be grounded in our physical experiences. We use conceptual metaphors like important = big, and argument = opposing forces. To realize AGI that can do most of what humans can do may require embodiment, such as operating with a physical robot. Researchers have combined language learning and robotics by creating virtual worlds where virtual robots simultaneously learn to follow instructions and to navigate within a house.
GPT-3 is a trained language model released in 2020 by the research lab Open AI that has shown that disembodied language may not be enough. With prompts, it can write humanlike news articles, short stories and poems. But in one demo, it wrote: “It takes two rainbows to jump from Hawaii to seventeen.”
“I’ve played around a lot with it,” Mitchell says. “It does incredible things. But it can also make some incredibly dumb mistakes.”
AGI might also require other aspects of our animal nature, like emotions, especially if humans expect to interact with machines in natural ways. Emotions are not mere irrational reactions. We’ve evolved them to guide our drives and behaviors. According to Ilya Sutskever, a cofounder and the chief scientist at OpenAI, they “give us this extra oomph of wisdom.” Even if AI doesn’t have the same conscious feelings we do, it may have code that approximates fear or anger. Already, reinforcement learning includes an exploratory element akin to curiosity.

Humans aren’t blank slates. We’re born with certain predispositions to recognize faces, learn language and play with objects. Machine-learning systems also require the right kind of innate structure to learn certain things quickly. How much structure, and what kind, is a matter of intense debate. Sutskever says building in how we think we think is “intellectually seductive.” However, “we want the best blank slate.”
One general neural-network structure Sutskever likes is called the transformer, a method for paying greater attention to important relationships between elements of an input. It’s behind current language models like GPT-3, and has also been applied to analyzing images, audio and video. “It makes everything better,” he says.
Thinking about thinking
AI itself may help us discover new forms of AI. There’s a set of techniques called AutoML, in which algorithms help optimize neural-network architectures or other aspects of AI models. AI also helps chip architects design better integrated circuits. Last year, Google researchers reported in Nature that reinforcement learning performed better than their in-house team at laying out some aspects of an accelerator chip they’d designed.
AGI’s arrival may be decades away. “We don’t understand our own intelligence,” Mitchell says, as much of it is unconscious. “And therefore, we don’t know what’s going to be hard or easy for AI.” What seems hard can be easy and vice versa — a phenomenon known as Moravec’s paradox, after the roboticist Hans Moravec. In 1988, Moravec wrote, “it is comparatively easy to make computers exhibit adult-level performance in solving problems on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a 1-year-old when it comes to perception and mobility.” Babies are secretly brilliant. In aiming for AGI, Precup says, “we are also understanding more about human intelligence, and about intelligence in general.”
Turing differentiated between general intelligence and humanlike intelligence. In his 1950 paper on the imitation game, he wrote, “May not machines carry out something which ought to be described as thinking but which is very different from what a man does?” His point: You don’t need to think like a person to have genuine smarts.
Grappling with ethics
In the 1942 short story “Runaround,” one of Isaac Asimov’s characters enumerated “the three fundamental Rules of Robotics.” Robots avoided causing or allowing harm to humans, they obeyed orders and they protected themselves, as long as following one rule didn’t conflict with preceding decrees.
We might picture Asimov’s “positronic brains” making autonomous decisions about harm to humans, but that’s not actually how computers affect our well-being every day. Instead of humanoid robots killing people, we have algorithms curating news feeds. As computers further infiltrate our lives, we’ll need to think harder about what kinds of systems to build and how to deploy them, as well as meta-problems like how to decide — and who should decide — these things.
This is the realm of ethics, which may seem distant from the supposed objectivity of math, science and engineering. But deciding what questions to ask about the world and what tools to build has always depended on our ideals and scruples. Studying an abstruse topic like the innards of atoms, for instance, has clear bearing on both energy and weaponry. “There’s the fundamental fact that computer systems are not value neutral,” says computer scientist Barbara Grosz of Harvard University, “that when you design them, you bring some set of values into that design.”
One topic that has received a lot of attention from scientists and ethicists is fairness and bias. Algorithms increasingly inform or even dictate decisions about hiring, college admissions, loans and parole. Even if they discriminate less than people do, they can still treat certain groups unfairly, not by design but often because they are trained on biased data. They might predict a person’s future criminal behavior based on prior arrests, for instance, even though different groups are arrested at different rates for a given amount of crime.
And confusingly, there are multiple definitions of fairness, such as equal false-positive rates between groups or equal false-negative rates between groups. A researcher at one conference listed 21 definitions. And the definitions often conflict. In one paper, researchers showed that in most cases it’s mathematically impossible to satisfy three common definitions simultaneously.
Another concern is privacy and surveillance, given that computers can now gather and sort information on their use in a way previously unimaginable. Data on our online behavior can help predict aspects of our private lives, like sexuality. Facial recognition can also follow us around the real world, helping police or authoritarian governments. And the emerging field of neurotechnology is already testing ways to connect the brain directly to computers (SN: 2/13/21, p. 24). Related to privacy is security — hackers can access data that’s locked away, or interfere with pacemakers and autonomous vehicles.
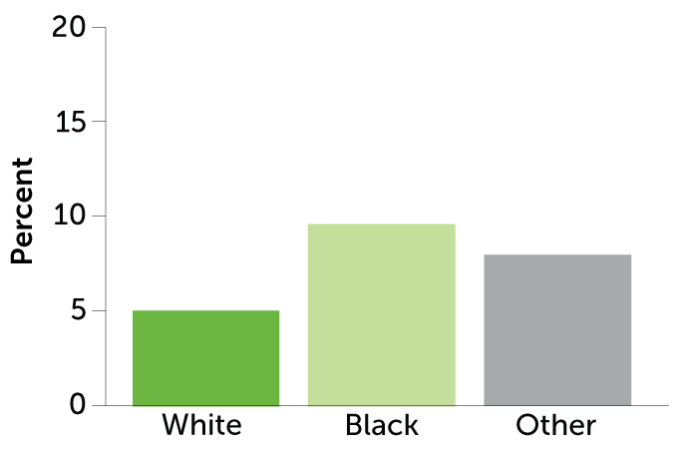
Predictive policing problems
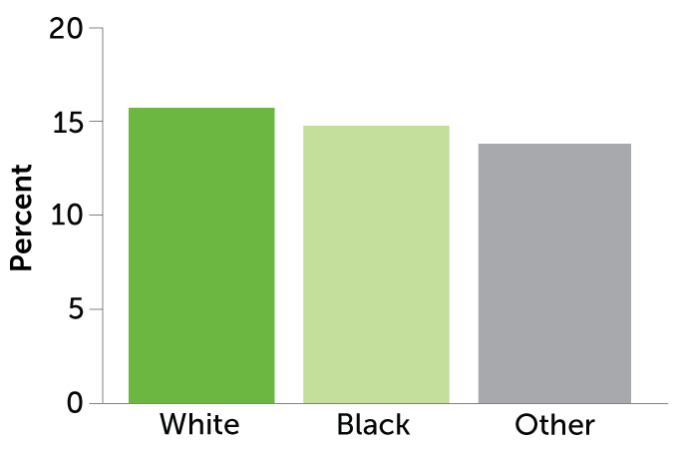
A predictive policing algorithm tested in Oakland, Calif., would target Black people at roughly twice the rate of white people (left) even though data from the same time period, 2011, show that drug use was roughly equivalent across racial groups (right).
Percent of population that would be targeted by predictive policing
Estimated percent of Oakland residents using drugs, by race
Computers can also enable deception. AI can generate content that looks real. Language models might be used to fill the internet with fake news and recruiting material for extremist groups (SN: 5/8/21 & 5/22/21, p. 22). Generative adversarial networks, a type of deep learning that can generate realistic content, can assist artists or create deepfakes, images or videos showing people doing things they never did (SN: 9/15/18, p. 12).
On social media, we also need to worry about polarization in people’s social, political and other views. Generally, recommendation algorithms optimize engagement (and platforms profit through advertising), not civil discourse. Algorithms can also manipulate us in other ways. Robo-advisers — chatbots for dispensing financial advice or providing customer support — might learn to know what we really need, or to push our buttons and upsell us on extraneous products.
Multiple countries are developing autonomous weapons that have the potential to reduce civilian casualties as well as escalate conflict faster than their minders can react. Putting guns or missiles in the hands of robots raises the sci-fi specter of Terminators attempting to eliminate humankind. They might not even be acting with bad intent, falsely reasoning that they are helping humankind by eliminating human cancer (an example of having no common sense). More near-term, automated systems let loose in the real world have already caused flash crashes in the stock market and sudden big leaps in book prices on Amazon. If AIs are charged with making life-and-death decisions, they then face the famous trolley problem, deciding whom or what to sacrifice when not everyone can win. Here we’re entering Asimov territory.
That’s a lot to worry about. Russell, of UC Berkeley, suggests where our priorities should lie: “Lethal autonomous weapons are an urgent issue, because people may have already died, and the way things are going, it’s only a matter of time before there’s a mass attack,” he says. “Bias and social media addiction and polarization are both arguably instances of failure of value alignment between algorithms and society, so they are giving us early warnings of how things can easily go wrong.”
There are also social, political and legal questions about how to manage technology in society. Who should be held accountable when an AI system causes harm? (For instance, “confused” self-driving cars have killed people.) How can we ensure more equal access to the tools of AI and their benefits, and make sure they don’t discriminate against groups or individuals? How will continuing automation of jobs affect employment? Can we manage the environmental impact of data centers, which use a lot of electricity? Should we preferentially employ explainable algorithms — rather than the black boxes of many neural networks — for greater trust and debuggability, even if it makes the algorithms poorer at prediction?
What can be done
Michael Kearns, a computer scientist at the University of Pennsylvania and coauthor of the 2019 book The Ethical Algorithm, puts the problems on a spectrum of manageability. At one end is what’s called differential privacy, the ability to add noise to a dataset of, say, medical records so that it can be shared usefully with researchers without revealing much about the individual records. We can now make mathematical guarantees about exactly how private individuals’ data should remain.
Somewhere in the middle of the spectrum is fairness in machine learning. Researchers have developed methods to increase fairness by removing or altering biased training data, or maximize certain types of equality — in loans, for instance — while minimizing reduction in profit. Still, some types of fairness will forever be in mutual conflict, and math can’t tell us which ones we want.
At the far end is explainability. As opposed to fairness, which can be analyzed mathematically in many ways, the quality of an explanation is hard to describe in mathematical terms. “I feel like I haven’t seen a single good definition yet,” Kearns says. “You could say, ‘Here’s an algorithm that will take a trained neural network and try to explain why it rejected you for a loan,’ but [the explanation] doesn’t feel principled.” Ultimately, if the audience doesn’t understand it, it’s not a good explanation, and measuring its success — however you define success — requires user studies.
Something like Asimov’s three laws won’t save us from robots that hurt us while trying to help us. And even if the list were extended to a million laws, the letter of a law is not identical to its spirit. One possible solution is what’s called inverse reinforcement learning, in which computers might learn to decipher what we really value based on our behavior.

Engineer, heal thyself
In the 1950 short story “The Evitable Conflict,” Asimov articulated what became a “zeroth law,” a law to supersede all others: “A robot may not harm humanity, or, by inaction, allow humanity to come to harm.” It should go without saying that the rule should apply with “roboticist” in place of “robot.” For sure, many computer scientists avoid harming humanity, but many also don’t actively engage with the social implications of their work, effectively allowing humanity to come to harm, says Margaret Mitchell, a computer scientist who co-led Google’s Ethical AI team and now consults with organizations on tech ethics. (She’s no relation to computer scientist Melanie Mitchell.)
One hurdle, according to Grosz, of Harvard, is that too many researchers are not properly trained in ethics. But she hopes to change that. Grosz and philosopher Alison Simmons began a program at Harvard called Embedded EthiCS, in which teaching assistants with training in philosophy are embedded in computer science courses and teach lessons on privacy or discrimination or fake news. The program has spread to MIT, Stanford and the University of Toronto.
“We try to get students to think about values and value trade-offs,” Grosz says. Two things have struck her. The first is the difficulty students have with problems that lack right answers and require arguing for particular choices. The second is, despite their frustration, “how much students care about this set of issues,” Grosz says.
Another way to educate technologists about their influence is to widen collaborations. According to Mitchell, “computer science needs to move from holding math up as the be-all and end-all, to holding up both math and social science, and psychology as well.” Researchers should bring in experts in these topics, she says.
Going the other way, Kearns says, they should also share their own technical expertise with regulators, lawyers and policy makers. Otherwise, policies will be so vague as to be useless. Without specific definitions of privacy or fairness written into law, companies can choose whatever’s most convenient or profitable.
When evaluating how a tool will affect a community, the best experts are often community members themselves. Grosz advocates consulting with diverse populations. Diversity helps in both user studies and technology teams. “If you don’t have people in the room who think differently from you,” Grosz says, “the differences are just not in front of you. If somebody says not every patient has a smartphone, boom, you start thinking differently about what you’re designing.”
According to Margaret Mitchell, “the most pressing problem is the diversity and inclusion of who’s at the table from the start. All the other issues fall out from there.”