Research is needed on how ocean carbon removal methods — such as iron fertilization and direct capture — could impact the environment.
Category: Uncategorized
A new method of making diamonds doesn’t require extreme pressure
Lab-grown diamonds can form at atmospheric pressure in a liquid of gallium, iron, nickel and silicon.
Tiny treadmills show how fruit flies walk
A method to force fruit flies to move shows the insects’ stepping behavior and holds clues to other animals’ brains and movement.
A decades-old mystery has been solved with the help of newfound bee species
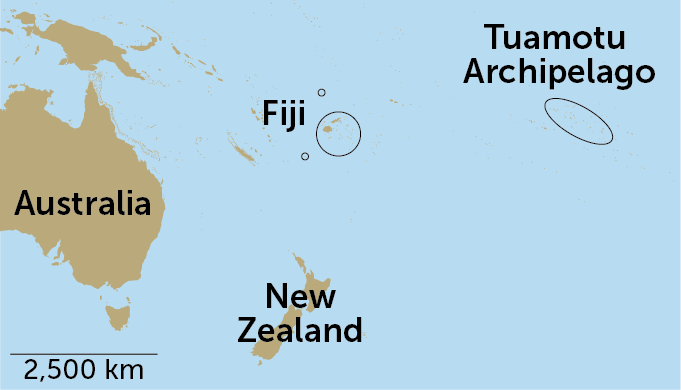
In 1965, renowned bee biologist Charles Michener described a new species of masked bee from “an entirely unexpected region,” the Tuamotu Archipelago of French Polynesia. Michener named the bee Hylaeus tuamotuensis and noted that its nearest relatives live in New Zealand — some 3,000 miles away across the Pacific Ocean. How did a small bee make such a big journey?
It turns out that the answer was buzzing above scientists’ heads all along. By swinging insect nets high up in the trees, researchers discovered eight species of Hylaeus bees that had never been described before, including six that live in Fiji.
The island nation lies between French Polynesia and Australia, where Hylaeus diversity is highest, so the scientists suspect that the ancestors of H. tuamotuensis reached their remote home by island-hopping across the Pacific. As individual bees moved from island to island, they steadily evolved into separate species, researchers report February 26 in Frontiers in Ecology and Evolution.
The island life of bees

Most bee species live in arid regions like the southwestern United States, says bee biologist Bryan Danforth of Cornell University, who was advised by the late Michener for his Ph.D. “We don’t think of bees as being terribly diverse in islands.”
Bee searchers usually snag their quarry by sweeping nets low to the ground. But during a trip to Fiji in 2019, evolutionary biologist James Dorey of Wollongong University in Australia took a different approach. He knew that some bees in Australia tend to fly in the canopy of eucalypt trees, or gum trees, and thought bees in Fiji might do the same. He equipped himself with a longer net and started swinging it skyward.
“As soon as I was able to sample a flowering tree, we were catching Hylaeus,” Dorey says. “It was clear that we had more than one [new] species from that one tree.”
Searching for bees in treetops is relatively rare. But “we’re starting to realize that, actually, there’s a lot of bee diversity up there,” Danforth says.

Dorey and his collaborators have a strong relationship with local Fijians, especially in Navai Village on the main island of Viti Levu, and with Fijian scientists like coauthor Marika Tuiwawa, a botanist at the University of the South Pacific. There is a lot of enthusiasm among Fijians for their native bees, Dorey says, and he hopes to train students there in bee collecting. Experts on Fiji’s bees, he says, should be Fijian.
While it’s clear that H. tuamotuensis is not alone in its remote island home, many mysteries remain: How did Hylaeus bees make it to the various islands and what path did they take?
It’s possible the bees were blown across the Pacific by storms, Danforth says, but he also thinks that their habit of nesting in wood may have something to do with the bees’ spread. “If you nest in wood and a piece of wood falls in the ocean, and that drifts thousands of kilometers and lands on a habitable spot, that’s a plausible way for these bees to disperse,” he says. “We know that other wood-nesting bees have done that.”
Four years on, the COVID-19 pandemic has a long tail of grief
March 11 marks the fourth anniversary of the World Health Organization’s declaration that the COVID-19 outbreak was a pandemic. COVID-19 hasn’t gone away, but there have been plenty of actions that suggest otherwise.
In May 2023, WHO announced COVID-19 was no longer a public health emergency (SN: 5/5/23). The United States shortly followed suit, which meant testing and treatments were no longer free (SN: 5/4/23). And on March 1 of this year, the U.S. Centers for Disease Control and Prevention loosened their isolation guidelines for people with COVID-19. Now the CDC says infected people can be around others as soon as a day after a fever subsides and symptoms are improving, even though someone is contagious during an infection for six to eight days, on average (SN: 7/25/22).
These outward signs of leaving the pandemic chapter behind neglect to acknowledge how many people cannot (SN: 10/27/21). Nearly 1.2 million people have died in the United States from COVID-19. Close to 9 million adults have long COVID. Nearly 300,000 children have lost one or both parents.
There has been little official recognition in the United States of the profound grief people have experienced and continue to experience. There is no federal monument to honor the dead — mourners have constructed their own memorials. A resolution to commemorate the first Monday of March as “COVID-19 Victims Memorial Day” awaits action by the U.S. Congress.
Many people are coping not just with the deaths of family and friends from COVID-19, but with how the pandemic robbed them of the chance to say goodbye to loved ones and grieve with their family and community. Researchers are studying the extent to which these losses rippled out into society and how the pandemic interrupted the grieving process.
Emily Smith-Greenaway, a demographer at the University of Southern California in Los Angeles, was part of team that estimated that for every one COVID-19 death, there are nine bereaved family members (SN: 4/4/22). Sarah Wagner, a social anthropologist at George Washington University in Washington, D.C., leads a project called Rituals in the Making, which is examining how the pandemic disrupted rituals and the experience of mourning through interviews with mourners and death care workers, among other research methods. Science News spoke with Smith-Greenaway and Wagner about their work. The interviews have been edited for length and clarity.
SN: Why is it important to estimate the number of close family members affected by COVID-19 deaths?
Smith-Greenaway: We typically quantify mortality events in terms of numbers of casualties. By shedding light explicitly on the concentric circles of people surviving each of the deaths, we offer a much more experiential perspective — the burden that a large-scale mortality event imposes on those who are still alive. It also allows us to kind of rescale the true sense of the magnitude of the crisis.
[With the number of deaths today,] our model demonstrates that about 10.5 million people have lost a close relative to COVID, [which includes] grandparents, parents, siblings, spouses and children. We’re not even capturing cousins, aunts, uncles. Think about how many children lost teachers or how many neighbors or friends or coworkers [died]. This is an underestimate when we’re thinking about the many people who are affected by each single death.
SN: What motivated the Rituals in the Making project?
Wagner: We began in May of 2020, and this was this period of heightened pandemic restriction and confinement. We posed what we saw as a fundamental question: How do we mourn when we cannot gather? Particularly in that first year, we were focused on the rituals around funeral, burial and commemorative practice and how they would be impacted and changed by the pandemic. In the last two years, [the project] has included the ways in which misinformation also compounds individual grief and more collective mourning.
A throughline in the research is that this mourning was interrupted and constrained by the conditions of the pandemic itself, but also troubled by politicization of the deaths. And then [there’s] this expectation that we move on, we push past the pandemic, and yet we have not acknowledged the enormity of the tragedy.
SN: Why are rituals and memorials important to grieving?
Wagner: We think about rituals as providing a means to respond to rupture. We are able to come together, gathering to stand before a coffin to say goodbye, or to have a wake, to sit down and have a meal with the bereaved. They are about providing an opportunity to remember and honor that loved one. But they are also about the living — a way of supporting the surviving family members, a way of helping them out of the chasm of that grief.
Memorials [such as a day of remembrance or a monument] are a nation saying, we recognize these lives and we anoint them with a particular meaning. We think about memorials as forms of acknowledgement and a way of making sense of major tragedies or major sacrifices.
In the context of the pandemic, the rituals that are broken and [the lack of] memorials at that national level help us see that the mourners have been left in many ways to take memory matters into their own hands. The responsibility has been pushed onto them at these acute moments of their own grief.
SN: How has the pandemic impacted survivors and the grieving process?
Smith-Greenaway: Societies have demographic memory. There is a generational effect any time we have a mortality crisis. A war or any large-scale mortality event lingers in the population, in the lives and memories of those who survived it.
This pandemic will stay with us for a very long time. [There are] young people who remember losing their grandma, but they couldn’t go see her in the hospital, or remember losing a parent in this sudden way because they brought COVID-19 home from school. So many lives were imprinted at such an early stage of life.
Wagner: Whether we are talking to the bereaved, members of the clergy, health care workers or staff from funeral homes, people describe the isolation. It is incredibly painful for families because they weren’t able to be with their loved one, to be able to touch someone, to hold their hand, to caress a cheek. People were left to wonder, “was my loved one aware? Were they confused? Were they in pain?” [After the death], not being able to have people into one’s home, not being able to go out. That sort of joy of having other people around you in your depths of grief — that was gone.
As the study progressed, [we learned about] the impact political divisiveness had on people’s grief. [Families were asked,] did the person have underlying health issues? What was the person’s vaccination status? It was as if the blame was getting shifted onto the deceased. Then to be confronted with, “this is all just a hoax,” or “[COVID-19 is] nothing worse than a bad cold.” To be a family member, and to struggle for recognition in the face of these conversations that their loved ones’ death and memory is not just dismissed, but in a way feels denied.
SN: How can society better support the need to grieve?
Smith-Greenaway: Bereavement policies are not very generous, as we would expect in America. Sometimes it’s one, two or three days. They’re also very restrictive, where it has to be a particular relation.
Think about kids. I’m a professor at a university. There’s this callous joke that college students just tell you their grandmother died because they don’t want to turn something in. This reflects how we treat bereavement as a society, especially for young people. Kids’ grief can often be misunderstood. It’s perceived to be bad behavior, that they’re acting out. I think we need comprehensive school policies that take better care to recognize how many kids are suffering losses in their lives.
Wagner: We’re enveloped in this silence around pandemic death. I think there’s a willingness to talk about the pandemic losses in other realms, the economic losses or the loss of social connection. Why is there this silence around 1.2 million deaths — the enormity of the tragedy?
If you know someone who has lost a loved one to COVID-19, talk to them about it. Ask them about that loved one. Just being an active part of conversations around memory can be a beautiful act. It can be a restorative act.
The blood holds clues to understanding long COVID
When I talk to immunologist Paul Morgan, he’s on the hunt for potentially life-altering drugs.
He’s got a call with a pharmaceutical company planned in the next half hour. His goal: persuade the company to supply his lab with a drug that might — maybe, hopefully, someday — ease some of the unrelenting symptoms of long COVID.
Morgan’s lab at Cardiff University in Wales has been studying people with the disease, including the first waves of patients, some of whom have been living with long COVID for more than two years (SN: 8/21/23). The “very long haulers,” he calls them. Their symptoms can include brain fog, fatigue, breathlessness and joint and muscle pain.
Morgan and his colleagues have pinpointed an immune system anomaly in the blood of some of these long haulers. A drug that targets that quirk might be one way to treat their disease. He’s quick to tell me that this research is in its early days. First, his team needs to get its hands on a drug. Then they need to do a clinical trial — at this stage, it’s still proof-of-concept. “Actual treatments are still some way off,” he says.
But the work is one in a surge of studies mining the blood for long COVID clues, potential biomarkers of the disease. A growing cadre of labs are starting to sketch out some of the shrouded figures at play in the once-seemingly inscrutable disease. It’s as if there’s a “picture that’s being revealed from the fog,” says Akiko Iwasaki, an immunologist and Howard Hughes Medical Institute investigator at Yale University.
That picture features a motley cast of molecular and cellular characters that could point scientists toward potential tests and treatments — both are currently lacking. Still, the full long COVID landscape is unquestionably complicated. Assorted actors tangle together in an immunological thicket that can make the disease seem impenetrable.
But Iwasaki thinks researchers can crack long COVID’s mysteries. In fact, recent work in the field has her feeling pretty excited. Yes, investigating long COVID is complex, she says. “But it’s definitely worth doing because many people are suffering.”
I spoke with Iwasaki, Morgan, and other researchers about long haulers and current work to illuminate the disease — and to get clarity on the less severe but still vexing symptoms that stuck around for months after my own COVID-19 infection.
Long COVID is not a single disease, which makes diagnosis and treatment difficult
Some 5 to 20 percent of COVID-19 cases develop into long COVID, though the exact number is hard to pin down. One formidable challenge is diagnosis. Does a person with bone-deep exhaustion and trouble concentrating on the pages of their book have the disease? There’s no test or nasal swab doctors can use to provide a definitive answer.
For diseases like diabetes and prostate cancer, scientists look for biomarkers in the blood — molecules that can serve as telltale signs of illness. But “we are not likely to come up with one biomarker or even one set of biomarkers to distinguish everyone with long COVID,” Iwasaki says.
The difficulty is that long COVID is not just one disease. It’s likely a collection of many diseases, she says, with varying sets of symptoms and triggers. Even defining long COVID is complicated. Last spring, researchers developed a long COVID scoring system that factors in a dozen signature symptoms. But more than 200 symptoms have been tied to the disease, and cases can vary greatly from person to person (SN: 11/17/22).
Today, in many doctors’ offices and clinics, homing in on a diagnosis means first ruling out other conditions. For example, after months of feeling wrung out and faded, with unexpected pain in my legs following a COVID-19 infection last year, my doctor ordered a slew of blood tests. She was looking for signs of rheumatoid arthritis, Lyme disease, thyroid hormone abnormalities and a handful of other conditions. Everything was negative. It’s called a “diagnosis of exclusion,” Morgan says. “You test for everything else, and when nothing comes back positive, you say, ‘well, it must be [long COVID], then.’”
He compares it to myalgic encephalomyelitis/chronic fatigue syndrome, or ME/CFS, another debilitating condition that also lacks clear diagnostic tests. “Many physicians don’t take it very seriously at all because of that.” That concern is even listed on the U.S. Centers for Disease Control and Prevention’s ME/CFS Web page. And it’s true of long COVID, too, says Wolfram Ruf, an immunologist at University Medical Center Mainz in Germany. “There’s still some misconception that this is just a psychological disease.” A 2022 survey found that a third of long COVID patients felt as if medical professionals dismissed their illness. And stories from frustrated long haulers continue to appear in the news.
Better diagnostics mean people suffering from long COVID’s myriad symptoms could put a firm label on their condition. That’s important, Morgan says. But tests that spot long COVID biomarkers in the blood could also do far more. “If those tests actually lead you to a mechanism and to a treatment,” he says, “then that’s transformational.”
A complicated cast of immune and other characters may contribute to long COVID
Morgan’s lab and others have zeroed in on immune proteins that defend us from bacteria and viruses. These proteins, part of a defense called complement, circulate in the blood, and get chopped up during an infection. The resulting fragments sound a “we’re under attack” alarm and help form a molecular machine that busts pathogens.
Once the infection clears, the fragments fade away. But in some people with long COVID, the alarm-raising fragments can linger in the blood, Morgan’s team reported February 14 in Med. That’s a sign that the defense system is still whipping up inflammation — in some cases, even years after a person’s initial COVID-19 infection. In January, a different group reported something similar in Science in a study of 113 COVID-19 patients.
Not everyone with long COVID will have complement abnormalities. Even in the patients Morgan studies, “there will be some people who have no changes in their complement markers at all.”
But for those who do, it can be a double-edged sword, he says. Turning complement on briefly can knock out some bugs, but keeping it on chronically can damage your cells.
There’s an ever-growing list of other blood-borne anomalies, too. A protein found in the brain can leak out into the blood in people with brain fog, scientists found in February. And long COVID patients can have low levels of the stress hormone cortisol, Iwasaki’s team reported in Nature in September. In some patients, she and others have also spotted other suspicious signs, like long-slumbering herpes viruses that reawaken and start infecting cells again. “Whether this is a cause or effect [of long COVID],” Iwasaki says, “we don’t know.” Usually, the immune system keeps these viruses under control.
In some people with long COVID, powerful immune players called T cells also seem to go out of whack. Scientists in England analyzing the blood of long COVID patients found T cells that release high levels of an alarm signal called interferon-gamma. That signal could serve as a potential biomarker in some patients, the study’s authors suggested.
“Perhaps there’s SARS-CoV-2 somewhere in the body that can’t be cleared.”
Nadia Roan
At the University of California, San Francisco, virologist and immunologist Nadia Roan’s team is also taking a look at T cells. In some long COVID patients, T cells that recognize SARS-CoV-2 can become exhausted, her team reported in Nature Immunology in January. And scientists know that tired-out T cells can have trouble wiping out infection.
“Perhaps there’s SARS-CoV-2 somewhere in the body that can’t be cleared,” Roan says. If a hidden reservoir of virus lurks in people’s tissues long-term, certain T cells might gather there for continued attack, eventually wearing the cells down. Last summer, a different team found viral traces in some people’s guts nearly two years after their initial infection. Scientists have also spotted signs of SARS-CoV-2 in other body tissues, including brain, lung and liver. These traces may be enough to irritate the immune system long term.
Residual virus isn’t likely to explain everything. “Different mechanisms may drive different forms of the disease,” Roan says. But together, work from her lab and others paints a portrait of an immune system under enduring duress. And as the pictures comes into focus, scientists are starting to explore new experiments, trials and treatments.
Clinical trials will test whether antiviral drugs can ease long COVID symptoms
Iwasaki and her colleagues are nearly done recruiting 100 people with long COVID for a randomized clinical trial of the antiviral drug Paxlovid. A similar trial by the National Institutes of Health is also in the works. That study aims to enroll 900 people and should conclude testing by this summer.
An idea targeted by both trials is that SARS-CoV-2 persists in the body, triggering symptoms. Scientists will follow participants as they take Paxlovid for 15 or 25 days. (For COVID-19 infection, the typical treatment length is five days.)

Iwasaki’s team also plans to scan participants’ blood for molecules that might predict a person’s response to Paxlovid. Suppose participants who improve after Paxlovid had high levels of certain blood molecules prior to treatment. Scientists could then measure those molecules in other people with long COVID to see if they might be good candidates for the drug. “There’s not one drug cure-all,” Iwasaki says, “but even knowing who might benefit is a huge thing.”
And though Morgan’s complement work is still at an early stage, he considers it a “strong lead to a potential therapy.” One bright spot is the number of complement-targeting drugs that already exist. Doctors currently use the drugs to treat certain blood disorders and other rare conditions. Morgan and other scientists have tried using some of these drugs to treat severe cases of acute COVID-19 infection, but large-scale trials didn’t pan out.
Now, he wants to repurpose those drugs for long COVID patients whose complement system has gone out of control. Dialing down those defenses might help quench the fire of chronic inflammation.
So far, Morgan hasn’t seen much interest from pharmaceutical companies. Repurposing generic drugs isn’t a big money maker. And Morgan’s team doesn’t envision long COVID patients needing to use the drugs long-term — another financial disincentive for companies. But when I email him later, he says his call after our interview went well. Morgan’s not naming the company yet but he knows that patients are standing by, waiting day after day for anything that will offer some relief.
For me, lingering symptoms turned the once-easy tasks of everyday life into energy-sucking feats performed while my body’s battery blinked down to zero. If I miscalculated and walked too fast or moved too much, I’d pay for it later and crash on the couch or in bed, sometimes taking days to recover. That symptom is known as post-exertional malaise and it’s common for people with long COVID.
But I was never officially diagnosed with the disease. Keeping up with doctors’ appointments felt daunting, and I wasn’t sure how much my doctor would be able to help. There may be many people who fall into this category, Morgan says — people who have long-term symptoms but lack clear-cut answers.
Though white women like myself are most likely to be diagnosed with the disease, in a survey from the U.S. Census Bureau, Hispanic and Black people were more likely to report long-lasting symptoms. Access to care could be one factor in the diagnosis discrepancy. Previous data have shown that people from these groups are less likely to have health insurance. Another factor may be the changeling nature of the disease itself. Long COVID can show up differently in different groups of people, scientists have found.
I’m lucky because my symptoms started improving after about six months. I knew I was mostly recovered the first time I went grocery shopping and carried my bags into the house by myself, without crashing afterwards. But so many others continue to struggle.
Morgan sees that firsthand. Since his paper came out, “I’ve been absolutely deluged by letters from patients,” he says. They ask to be tested and if he has drugs that can treat them. For Morgan, those letters show the depth of the problem.
“I reply to them all,” he says.
Readers discuss cholesterol treatments and AI


Get low (cholesterol’s version)
An experimental genetic treatment called VERVE-101 can deactivate a cholesterol-raising gene in people with hypercholesterolemia, Meghan Rosen reported in “Base editing can lower cholesterol” (SN: 1/27/24, p. 8).
Rosen wrote that researchers are testing to see what dosage of VERVE-101 is most effective. Given that the treatment edits a gene, reader Linda Ferrazzara wondered why the dose matters.
Too low a dose may mean that not enough VERVE-101 makes it to the liver, where it turns off the gene, Rosen says. If too few cells have the gene switched off, patients will not experience the drug’s cholesterol-lowering effects. If cholesterol levels remain high after an initial treatment, a second infusion of the drug may help, Rosen says. But the developers prefer for the treatment to be one dose.
Reader Jack Miller asked whether VERVE-101 affects germ cells, which give rise to sperm and egg cells.
In mice, scientists have found that most of the drug ends up in the liver, and none goes to the germ line, Rosen says. The offspring of treated mice are also unaffected by the drug. So if the children of treated patients also have hypercholesterolemia, those kids would still need their own treatment, she says.
AI etiquette
To develop better safeguards, scientists are studying how people have tricked AI chatbots into answering harmful questions that the AI have been trained to decline, such as how to build a dangerous weapon, Emily Conover reported in “Chatbots behaving badly” (SN: 1/27/24, p. 18).
Reader Linda Ferrazzara wondered if AI chatbots have been trained on languages other than English.
AI chatbots like ChatGPT are based on large language models, or LLMs, a type of generative AI typically trained on vast swaths of internet content. Many of the biggest, most capable LLMs right now are tailored to English speakers, Conover says. Although those LLMs have some ability to write in other languages, most of their training data is in English. But there are language models designed to use other languages, she says. Efforts so far have focused on languages that are widely spoken and written, and for which large amounts of training data are available, such as Mandarin.
Ferrazzara also asked if boosting computing power could help the bots better defend against trickery.
LLMs already use a lot of computing power, and it will only increase as people use LLMs more and more, Conover says. But even if increased power would make establishing safeguards easier, we need to recognize that greenhouse gas emissions linked to such energy-intensive calculations contribute to climate change, she says. “The time and energy needed to respond to a chatbot query is not something we want to overlook while waiting for computers to improve.”
Many of the defensive techniques described in the story screen for harmful questions. Reader Mike Speciner wondered if filtering the responses to those questions would be easier.
Some filters like this are already applied on some chatbots, Conover says. For example, Microsoft’s Bing AI tends to cut off its answers if it wades into forbidden territory. These filters are more general, rather than targeted specifically at one kind of attack. “To avoid letting bad stuff slip through, they may cast too wide of a net, filtering out innocuous answers as well as dangerous ones and making the user’s experience worse,” Conover says. What’s more, an attacker who knows how the LLM’s self-filtering works may figure out a way to fool that filter.
Correction
“Saving lives with safe injection” incorrectly described Elizabeth Samuels of UCLA as an epidemiologist and emergency medicine physician (SN: 2/10/24, p. 16). She is an emergency and addiction medicine physician. That story also mistakenly stated that drug policy consultant Edward Krumpotich helped write the 2023 legislation in Minnesota that authorized funding for an overdose prevention center. He advocated for that legislation but did not help write it.
Why large language models aren’t headed toward humanlike understanding
Apart from the northward advance of killer bees in the 1980s, nothing has struck as much fear into the hearts of headline writers as the ascent of artificial intelligence.
Ever since the computer Deep Blue defeated world chess champion Garry Kasparov in 1997, humans have faced the prospect that their supremacy over machines is merely temporary. Back then, though, it was easy to show that AI failed miserably in many realms of human expertise, from diagnosing disease to transcribing speech.
But then about a decade ago or so, computer brains — known as neural networks — received an IQ boost from a new approach called deep learning. Suddenly computers approached human ability at identifying images, reading signs and enhancing photographs — not to mention converting speech to text as well as most typists.
Those abilities had their limits. For one thing, even apparently successful deep learning neural networks were easy to trick. A few small stickers strategically placed on a stop sign made an AI computer think the sign said “Speed Limit 80,” for example. And those smart computers needed to be extensively trained on a task by viewing numerous examples of what they should be looking for. So deep learning produced excellent results for narrowly focused jobs but couldn’t adapt that expertise very well to other arenas. You would not (or shouldn’t) have hired it to write a magazine column for you, for instance.
But AI’s latest incarnations have begun to threaten job security not only for writers but also a lot of other professionals.
“Now we’re in a new era of AI,” says computer scientist Melanie Mitchell, an artificial intelligence expert at the Santa Fe Institute in New Mexico. “We’re beyond the deep learning revolution of the 2010s, and we’re now in the era of generative AI of the 2020s.”
Generative AI systems can produce things that had long seemed safely within the province of human creative ability. AI systems can now answer questions with seemingly human linguistic skill and knowledge, write poems and articles and legal briefs, produce publication quality artwork, and even create videos on demand of all sorts of things you might want to describe.
Many of these abilities stem from the development of large language models, abbreviated as LLMs, such as ChatGPT and other similar models. They are large because they are trained on huge amounts of data — essentially, everything on the internet, including digitized copies of countless printed books. Large can also refer to the large number of different kinds of things they can “learn” in their reading — not just words but also word stems, phrases, symbols and mathematical equations.
By identifying patterns in how such linguistic molecules are combined, LLMs can predict in what order words should be assembled to compose sentences or respond to a query. Basically, an LLM calculates probabilities of what word should follow another, something critics have derided as “autocorrect on steroids.”
Even so, LLMs have displayed remarkable abilities — such as composing texts in the style of any given author, solving riddles and deciphering from context whether “bill” refers to an invoice, proposed legislation or a duck.
“These things seem really smart,” Mitchell said this month in Denver at the annual meeting of the American Association for the Advancement of Science.
LLMs’ arrival has induced a techworld version of mass hysteria among some experts in the field who are concerned that run amok, LLMs could raise human unemployment, destroy civilization and put magazine columnists out of business. Yet other experts argue that such fears are overblown, at least for now.
At the heart of the debate is whether LLMs actually understand what they are saying and doing, rather than just seeming to. Some researchers have suggested that LLMs do understand, can reason like people (big deal) or even attain a form of consciousness. But Mitchell and others insist that LLMs do not (yet) really understand the world (at least not in any sort of sense that corresponds to human understanding).
“What’s really remarkable about people, I think, is that we can abstract our concepts to new situations via analogy and metaphor.”
Melanie Mitchell
In a new paper posted online at arXiv.org, Mitchell and coauthor Martha Lewis of the University of Bristol in England show that LLMs still do not match humans in the ability to adapt a skill to new circumstances. Consider this letter-string problem: You start with abcd and the next string is abce. If you start with ijkl, what string should come next?
Humans almost always say the second string should end with m. And so do LLMs. They have, after all, been well trained on the English alphabet.
But suppose you pose the problem with a different “counterfactual” alphabet, perhaps the same letters in a different order, such as a u c d e f g h i j k l m n o p q r s t b v w x y z. Or use symbols instead of letters. Humans are still very good at solving letter-string problems. But LLMs usually fail. They are not able to generalize the concepts used on an alphabet they know to another alphabet.
“While humans exhibit high performance on both the original and counterfactual problems, the performance of all GPT models we tested degrades on the counterfactual versions,” Mitchell and Lewis report in their paper.
Other similar tasks also show that LLMs do not possess the ability to perform accurately in situations not encountered in their training. And therefore, Mitchell insists, they do not exhibit what humans would regard as “understanding” of the world.
“Being reliable and doing the right thing in a new situation is, in my mind, the core of what understanding actually means,” Mitchell said at the AAAS meeting.
Human understanding, she says, is based on “concepts” — basically mental models of things like categories, situations and events. Concepts allow people to infer cause and effect and to predict the probable results of different actions — even in circumstances not previously encountered.
“What’s really remarkable about people, I think, is that we can abstract our concepts to new situations via analogy and metaphor,” Mitchell said.
She does not deny that AI might someday reach a similar level of intelligent understanding. But machine understanding may turn out to be different from human understanding. Nobody knows what sort of technology might achieve that understanding and what the nature of such understanding might be.
If it does turn out to be anything like human understanding, it will probably not be based on LLMs.
After all, LLMs learn in the opposite direction from humans. LLMs start out learning language and attempt to abstract concepts. Human babies learn concepts first, and only later acquire the language to describe them.
So LLMs are doing it backward. In other words, perhaps reading the internet might not be the correct strategy for acquiring intelligence, artificial or otherwise.
On hot summer days, this thistle is somehow cool to the touch
In the mountains of southern Spain, one type of thistle plant seems to have built-in air conditioning.
The flowers of the thistle Carlina corymbosa are, on average, about 3 degrees Celsius cooler than the surrounding air, ecologist Carlos Herrera reports February 13 in Ecology. The most extreme cooling — sometimes up to 10 degrees C — occurs during the hottest part of the day. This means when the air temperature reaches a sweltering 45° C, the plant’s flowers can remain close to a relatively cool 35° C.
“Those are substantial coolings relative to the air next to it,” says Christopher Still, an ecologist at Oregon State University in Corvallis who was not involved in the work. “It’s a nice, careful study.”
In Spain’s Sierra de Cazorla mountain range, scorching summers leave many plants dead, dried out or dormant. This brown sea is intermittently broken by bursts of yellow, as C. corymbosa improbably peeks its flowers above the vegetation. When Herrera, of the Spanish National Research Council in Sevilla, touched one of the flower heads during the peak of the day’s heat on a recent trek, he found it pleasantly cool.
Herrera was there to study the relationship between the region’s plants and their pollinators. He bent to touch the thistle because he “was checking for the presence of nectar in the flower head,” he says, and then became curious about why the flower felt chilled.
Using an electric thermometer, he measured the temperatures of seven different thistles across two sites and multiple days per flower. He found the flowers consistently cooled down as the day grew hotter.
Many plants cool down by passively allowing water to evaporate through pores, a process called transpiration that is analogous to humans beating the heat by sweating (SN: 2/27/06). Most research has focused on how leaves keep cool, but in many cases, leaves don’t get colder than the surrounding air. When they do, Herrera reports, the difference in temperature is less drastic than seen in the thistle flowers.
There’s probably some truth to the idea that the thistle cools itself down more than leaves, but because flowers and leaves are measured differently, it’s hard to say for sure, Still says.
Because the thistles started cooling down at the hottest part of the day, it’s possible that the plants are actively turning a self-refrigerating mechanism on and off.
The idea that plants might be controlling their internal temperatures took off in the late 1980s, and is known as “limited homeothermy.” However, this is a rare skill among plants, Still says. A 2022 study he led found no evidence that leaves in forest canopies across North and Central America were cooler than the air around them.
Both Herrera and Still think that something about the thistle flower’s shape and structure enables it to cool off so effectively.
Herrera suspects that as water within the thistle evaporates, it takes heat with it, and because of the flower’s physical form, that heat isn’t being replaced by the sun’s warmth. This might allow the plant to cool below the air temperature. Herrera dubs this the “botijo effect,” because “it is the same principle by which porous sweating pitchers” — called botijos in Spanish — “cool themselves in dry, hot air.” This idea needs to be tested, however.
Herrera and Still are both curious to know if being cooler than the surrounding air provides any benefit to the thistle, such as by attracting pollinators trying to escape the oppressive summer heat. Herrera plans to see if other thistles in southern Spain show the same cooling effect and has also mapped out an experiment to probe how limiting the plant’s access to water may influence its cooling ability.
“There’s a lot of value in old-fashioned naturalism,” Still says. “This one study could lead to lots of cool follow-on work.”
How two outsiders tackled the mystery of arithmetic progressions

Consider this sequence of numbers: 5, 7, 9. Can you spot the pattern? Here’s another with the same pattern: 15, 19, 23. One more: 232, 235, 238.
“Three equally spaced things,” says Raghu Meka, a computer scientist at UCLA. “That’s probably the simplest pattern you can imagine.”
Yet for almost a century, mathematicians in the field of combinatorics have been puzzling out how to know whether an endless list of numbers contains such a sequence, called an arithmetic progression. In other words, is there a way to be mathematically certain that a set contains a sequence of three or more evenly spaced numbers, even if you don’t know much about how the numbers in the set were selected or what the progression might be?
Progress on the question has been slow, even plodding. But last year, Meka and Zander Kelley, a Ph.D. computer science student at the University of Illinois Urbana-Champaign, surprised mathematicians by making an exponential leap. The researchers are outsiders in combinatorics, which is concerned with counting configurations of numbers, points or other mathematical objects. And the duo didn’t set out to tackle the mystery of arithmetic progressions.
Kelley and Meka were instead investigating abstract games in computer science. The pair sought a mathematical tool that might help them understand the best way to win a particular type of game over and over again. “I’m super-interested in a collection of techniques that fall under this umbrella called structure versus randomness,” Kelley says. Some of the earliest progress on arithmetic progressions relied on such techniques, which is what led Kelley and Meka to dive into the topic.
The mystery of whether arithmetic progressions will show up is just one of many mathematical questions related to order versus disorder in sets of objects. Understanding order — and when and where patterns must emerge — is a recurring theme in many branches of math and computer science.
Another example of order in objects says that any group of six people must contain either a group of at least three mutual acquaintances (all three know each other) or a group of at least three complete strangers (no one knows another). Research has shown that it doesn’t matter who they are, where they are from or how they were selected. There’s something powerful, maybe almost spooky, about the fact that we can say this — and make other similar claims about structure in sets — with mathematical certainty.
Solving the mystery of arithmetic progressions might open doors to investigating more complex relationships among numbers in a set — gaps that change in more elaborate ways, for instance. “These are more sophisticated versions of the same theorems,” says Bryna Kra, a mathematician at Northwestern University in Evanston, Ill. “Typically, once you see arithmetic progressions … you see other patterns.”
After publishing their work on arithmetic progressions, Kelley and Meka, with Shachar Lovett of the University of California, San Diego, imported techniques from their investigations of arithmetic progressions into a different context. The researchers solved a question in communication complexity, a subfield of theoretical computer science concerned with transmitting data efficiently between parties who have only partial information.
What’s more, knowing that certain mathematical structures have to appear in certain situations can be useful in real-world communication networks and for image compression.
Potential applications aside, researchers who study arithmetic progressions — or other facets of purely theoretical mathematics — are often motivated more by sheer curiosity than any practical payoff. The fact that questions about such simple patterns and when they appear remain largely unanswered is, for many, reason enough to pursue them.
What are arithmetic progressions?
Let’s take a moment to get our hands on some sets of numbers and the arithmetic progressions those sets contain, starting with the prime numbers, perennial favorites of math enthusiasts. A prime number is any whole number divisible only by itself and by 1; the first 10 primes are 2, 3, 5, 7, 11, 13, 17, 19, 23 and 29. Within those numbers, we can find a few arithmetic progressions. The numbers 3, 5 and 7 form a three-term arithmetic progression with a gap of two. But the numbers in a progression don’t have to follow each other immediately within the larger set: The numbers 5, 11, 17, 23 and 29 form a five-term arithmetic progression with a gap of six.
Within a finite set of numbers, it’s straightforward to determine whether there are any arithmetic progressions. It might be tedious depending on the set, but it’s not mysterious. For infinite sets of numbers, though, the question gets interesting.
The primes go on forever, and mathematicians have asked many — and answered some — questions about arithmetic progressions within them. Is there a longest possible arithmetic progression, a cap on the number of terms, in the primes? Or, can you find a progression of any finite length if you look long enough? In 2004, mathematicians proved that the latter is true. But questions including how far along the number line you have to look to find an arithmetic progression with a given number of terms or a given gap size remain active areas of research, for the primes and for other sets.
A simple arithmetic progression

The primes contain infinitely many arithmetic progressions, but some infinite sets contain none. Consider the powers of 10: 1, 10, 100, 1,000…. The gaps between consecutive terms get bigger fast — 9, 90, 900…. And none of them are the same. Playing around with the numbers a bit, you can convince yourself that no two powers of 10, whether consecutive or not, have the same gap as any other pair.
With that context, we now approach a question at the heart of this research: Why do some sets have arithmetic progressions while others don’t? One big difference between the primes and powers of 10 is that there are a lot more primes than powers of 10. Sort of. Both sets are infinite, but if you pick any arbitrary number as a cutoff and look at how many primes or powers of 10 there are below that number, the primes win every time. There are four primes from 1 to 10, versus only two powers of 10. There are 25 primes from 1 to 100 and only three powers of 10. The primes don’t just win every time, they win by a lot, and the amount they win by keeps increasing. In this way, the primes are “denser” — in an intuitive and technical sense — than the powers of 10.
A sparse enough set of numbers can have gaps arranged in ways that manage to avoid arithmetic progressions. Too dense, though, and the set can’t avoid having gaps that match up. In the 20th century, mathematicians settled on a way to measure that density. They are now looking for the density above which arithmetic progressions must appear.
Density in infinite sets
The study of arithmetic progressions in sets of whole numbers began in earnest in 1936, when Hungarian mathematicians Paul Erdős and Pál Turán posited that any set of whole numbers that is dense enough must contain arithmetic progressions of any desired length.
For finite sets, it’s easy to understand what density is. In the set of whole numbers between 1 and 10, the primes have a density of 4/10, or 0.4. But if we want to understand the density of the entire unending collection of prime numbers within the entire unending collection of the whole numbers, we need to find a way to make sense of infinity divided by infinity, or ∞/∞.

Mathematicians use a concept called asymptotic density to wrangle with the density of an infinite set of whole numbers. The basic idea is to choose some number as a cutoff point, N, and see what happens as N increases. If the density tends toward some fixed number, that is the set’s asymptotic density.
Let’s return to the powers of 10, whose density decreases across the number line. As you go out farther and farther, the proportion of whole numbers that are powers of 10 approaches zero — so the set has an asymptotic density of zero. Other sets have a positive asymptotic density, and some never settle down into an asymptotic density at all.
What Erdős and Turán proposed is that any set of numbers with positive, rather than zero, asymptotic density must contain at least one arithmetic progression. For some sets, it’s obvious (the even numbers have an asymptotic density of 0.5 and definitely contain arithmetic progressions). But proving it for any arbitrary set of numbers turned out to be a challenge.
It wasn’t until 1953 that German-British mathematician Klaus Roth proved the conjecture, opening the door to a more nuanced understanding of the role density plays in arithmetic progressions. He showed that any set with positive asymptotic density must contain at least one three-term arithmetic progression, or 3-AP. His argument relied on proving that dense enough pseudorandom sets — those that might not truly be chosen randomly but have the general properties of random sets — must contain arithmetic progressions. Then he developed a way to zoom in on parts of non-pseudorandom sets and show that, if the initial set is dense enough, these zoomed-in areas must be structured in ways that guarantee the presence of an arithmetic progression.
In early 2021, Kelley and Meka were investigating a problem in complexity theory called parallel repetition of games. Don’t think Monopoly or chess; the “games” the researchers were thinking about won’t be making Hasbro money any time soon. “We have a tendency to call anything a game if it has turns,” says Kelley. In the typical games Kelley and Meka were looking at, the players have access to different information and have to work together to find an answer to a question. But they can’t communicate during the game, so they must decide on a strategy beforehand. Kelley and Meka sought to determine how to maximize the chances that the players win many games in a row.
It’s not quite a hop, skip and a jump from parallel repetition of games to arithmetic progressions, but Kelley and Meka got there fairly quickly. “Maybe in a month we were at the 3-AP problem,” Meka says. Previous research on parallel repetition of games had used structure versus randomness arguments. Because Roth’s work on arithmetic progressions was the first to use such a technique, Kelley and Meka were interested in that work in its original habitat.
“In theoretical computer science, people are looking outward to math for some tools that they could use, and unless you’re ready to get yourself into some serious trouble, usually you see if you can use the tools, and then if you can’t, you move on,” Kelley says. “You don’t try to go open them up and see what they’re like.” But he and Meka did just that, knowing that they might go down a deep rabbit hole and end up with nothing to show for their time and effort. They dug into Roth’s arguments — as well as more recent research on the same subject — to see if they could push the work further. And so they found themselves staring down arithmetic progressions.
Reaching new limits
Roth’s contribution was more powerful than just showing that any set with positive asymptotic density must contain a 3-AP. He also proved that some sets with asymptotic density of zero, if the density tends toward zero slowly enough as you go out along the number line, must also contain at least one 3-AP.
Think of the density as having to pass beneath a limbo bar. If a set gets sparse too slowly, it can’t make it under and it must contain an arithmetic progression. But a set that approaches a density of zero quickly enough ducks under. For that set, anything goes: It may or may not have such a progression.
Roth’s initial proof found an upper limit to where the limbo bar must be. He showed that any set whose density approaches zero at a rate similar to or slower than the expression 1/log(log(N)) must contain at least one arithmetic progression. Log means to take the logarithm, and remember that N is the number chosen as the arbitrary cutoff in an infinite set. We’re considering what happens as N increases.
Logarithms grow slowly, roughly akin to the number of digits a number has. The logarithm of 1 is zero, of 10 is 1, of 100 is 2, of 1,000 is 3, and so on. But taking the logarithms of those logarithms gives much more sluggish growth. To nudge log(log(N)) from zero to 1, we have to move N from 10 to 10 billion. Dividing 1 by this double log, as appears in Roth’s work, we get a density that just plods toward zero.
Several years earlier, in 1946, mathematician Felix Behrend had investigated the lower limit of the limbo bar. He developed a recipe for cooking up sets without 3-APs, showing that any such set must be extremely sparse indeed. His limit was a density that goes to zero at approximately the same rate as 1/e(log(N))^½. That expression might not look familiar, but there’s an exponential function in the denominator. The log and ½ power slow things down a bit, but the whole expression goes to zero much faster than the double log Roth later found.
In the last few decades, researchers have been attempting to close the gap between Roth-style estimates of the sparsest sets that must contain a 3-AP and Behrend-style estimates of the densest sets that do not contain one. In 2020, mathematicians Thomas Bloom of the University of Oxford and Olof Sisask of Stockholm University broke what had come to be known as the logarithmic barrier for the Roth-style upper limit of the limbo bar, showing that any set with a density that goes to zero more slowly than 1/log(N) must contain at least one 3-AP. The work was seen as a breakthrough in the field, though the upper limit was still closer to the previous best-known upper limit than to Behrend’s lower limit.
Kelley and Meka pushed the upper limit down dramatically. Their result was a rate that goes to zero at approximately the same rate as 1/e(log(N))^1/11. That formula looks eerily similar to Behrend’s lower limit. For the first time ever, the upper and lower limits are within shooting distance of each other. Closing that gap would reveal the specific location of the limbo bar and thus give a clear answer to which sets must contain at least one 3-AP.
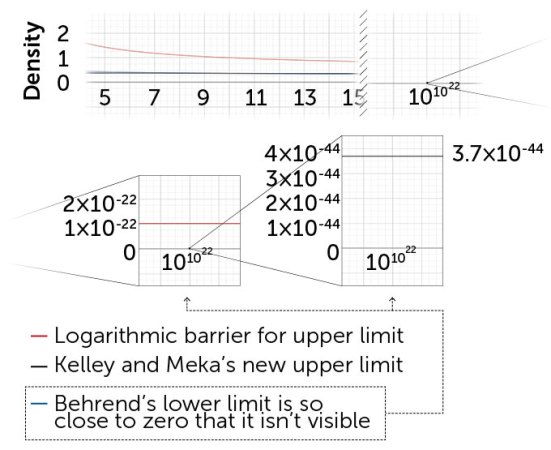
Headed to zero
How quickly a set’s density approaches zero as you move far out along the number line (insets) can reveal whether that set must contain an arithmetic progression. In 2023, computer scientists Zander Kelley and Raghu Meka showed that if the density approaches zero at a rate roughly similar to or slower than the black line above, the set must contain a progression. This upper limit is dramatically lower than “the logarithmic barrier” (broken in 2020 and shown in red), but it is still a long way from the lower limit (identified by Felix Behrend decades ago).
Upper and lower limits for sets that contain an arithmetic progression
What’s next?
When Kelley and Meka started on the 3-AP problem, they thought they would probably just poke around to identify the barriers to moving the upper limit down. A year later, the two were writing a paper about their breakthrough. “I think one thing that kept us going was it never felt like we were completely hitting a wall,” Meka says. “It always felt like we were either learning something useful, or we were actually making progress.”
Meka describes their overall approach, based on Roth’s early techniques, as exploiting a “wishful dichotomy” between randomness and structure. They developed a definition of pseudorandomness for their work and showed that for this definition, any dense enough pseudorandom set must contain at least one arithmetic progression.
After handling the pseudorandom case, the team considered more structured sets of numbers and showed that those sets too had to exhibit the desired patterns. Finally, Kelley and Meka expanded from these types of sets to all large enough sets of numbers, proving that those sets must have the properties of either the pseudorandom or the structured sets.
“Three equally spaced things. That’s probably the simplest pattern you can imagine.”
Raghu Meka
The most remarkable thing about Kelley and Meka’s work is that they were able to make such dramatic progress without developing a new approach to arithmetic progressions. Though they brought new insights and established new connections to previous work, they did not create new machinery.
“It just seemed completely intractable to push those techniques through,” Sisask says, “until this paper by Kelley and Meka landed in my inbox.” He and Bloom, who had previously broken the logarithmic barrier, “spent a while digesting the paper and talking about it until we understood it in our own language,” he says.
Mathematicians and computer scientists tend to use some different notation and terminology, but Sisask, Bloom and other experts in the field quickly recognized the work as solid. After digesting the arguments, Sisask and Bloom wrote an explanation of the work, with some subtle technical improvements, geared toward other researchers in combinatorics. Several months later, the team coaxed the upper limit down a tiny bit more, getting a new bound of 1/e(log(N))^1/9.
Combinatorics researchers are still trying to figure out how low they can go. Will they be able to push the upper limit all the way down to the best known lower limit, or will there always be a little gap where our knowledge is incomplete? Kelley and Meka are using the tools they honed on arithmetic progressions to continue work on problems in complexity theory and other areas of theoretical computer science.
When I asked Meka how two computer scientists made such a big advance on a mathematics problem that had stumped combinatorics experts for years, he said he isn’t sure. He thinks maybe their edge came from being fresh to the challenge.
“The problem has been around for a long time and progress seemed pretty stuck,” he says. In fact, after he and Kelley were well on their way to publishing, Kelley says he ran across a blog post from 2011 that outlined exactly why mathematicians were pessimistic about the very approach that the two had eventually used.
“People thought that these techniques couldn’t push beyond existing barriers,” Meka says, “but maybe we didn’t know that the barriers existed.”