An experimental genetic treatment called VERVE-101 can deactivate a cholesterol-raising gene in people with hypercholesterolemia, Meghan Rosen reported in “Base editing can lower cholesterol” (SN: 1/27/24, p. 8).
Rosen wrote that researchers are testing to see what dosage of VERVE-101 is most effective. Given that the treatment edits a gene, reader Linda Ferrazzara wondered why the dose matters.
Too low a dose may mean that not enough VERVE-101 makes it to the liver, where it turns off the gene, Rosen says. If too few cells have the gene switched off, patients will not experience the drug’s cholesterol-lowering effects. If cholesterol levels remain high after an initial treatment, a second infusion of the drug may help, Rosen says. But the developers prefer for the treatment to be one dose.
Reader Jack Miller asked whether VERVE-101 affects germ cells, which give rise to sperm and egg cells.
In mice, scientists have found that most of the drug ends up in the liver, and none goes to the germ line, Rosen says. The offspring of treated mice are also unaffected by the drug. So if the children of treated patients also have hypercholesterolemia, those kids would still need their own treatment, she says.
AI etiquette
To develop better safeguards, scientists are studying how people have tricked AI chatbots into answering harmful questions that the AI have been trained to decline, such as how to build a dangerous weapon, Emily Conover reported in “Chatbots behaving badly” (SN: 1/27/24, p. 18).
Reader Linda Ferrazzara wondered if AI chatbots have been trained on languages other than English.
AI chatbots like ChatGPT are based on large language models, or LLMs, a type of generative AI typically trained on vast swaths of internet content. Many of the biggest, most capable LLMs right now are tailored to English speakers, Conover says. Although those LLMs have some ability to write in other languages, most of their training data is in English. But there are language models designed to use other languages, she says. Efforts so far have focused on languages that are widely spoken and written, and for which large amounts of training data are available, such as Mandarin.
Ferrazzara also asked if boosting computing power could help the bots better defend against trickery.
LLMs already use a lot of computing power, and it will only increase as people use LLMs more and more, Conover says. But even if increased power would make establishing safeguards easier, we need to recognize that greenhouse gas emissions linked to such energy-intensive calculations contribute to climate change, she says. “The time and energy needed to respond to a chatbot query is not something we want to overlook while waiting for computers to improve.”
Many of the defensive techniques described in the story screen for harmful questions. Reader Mike Speciner wondered if filtering the responses to those questions would be easier.
Some filters like this are already applied on some chatbots, Conover says. For example, Microsoft’s Bing AI tends to cut off its answers if it wades into forbidden territory. These filters are more general, rather than targeted specifically at one kind of attack. “To avoid letting bad stuff slip through, they may cast too wide of a net, filtering out innocuous answers as well as dangerous ones and making the user’s experience worse,” Conover says. What’s more, an attacker who knows how the LLM’s self-filtering works may figure out a way to fool that filter.
Correction
“Saving lives with safe injection” incorrectly described Elizabeth Samuels of UCLA as an epidemiologist and emergency medicine physician (SN: 2/10/24, p. 16). She is an emergency and addiction medicine physician. That story also mistakenly stated that drug policy consultant Edward Krumpotich helped write the 2023 legislation in Minnesota that authorized funding for an overdose prevention center. He advocated for that legislation but did not help write it.
Apart from the northward advance of killer bees in the 1980s, nothing has struck as much fear into the hearts of headline writers as the ascent of artificial intelligence.
Ever since the computer Deep Blue defeated world chess champion Garry Kasparov in 1997, humans have faced the prospect that their supremacy over machines is merely temporary. Back then, though, it was easy to show that AI failed miserably in many realms of human expertise, from diagnosing disease to transcribing speech.
But then about a decade ago or so, computer brains — known as neural networks — received an IQ boost from a new approach called deep learning. Suddenly computers approached human ability at identifying images, reading signs and enhancing photographs — not to mention converting speech to text as well as most typists.
Those abilities had their limits. For one thing, even apparently successful deep learning neural networks were easy to trick. A few small stickers strategically placed on a stop sign made an AI computer think the sign said “Speed Limit 80,” for example. And those smart computers needed to be extensively trained on a task by viewing numerous examples of what they should be looking for. So deep learning produced excellent results for narrowly focused jobs but couldn’t adapt that expertise very well to other arenas. You would not (or shouldn’t) have hired it to write a magazine column for you, for instance.
But AI’s latest incarnations have begun to threaten job security not only for writers but also a lot of other professionals.
“Now we’re in a new era of AI,” says computer scientist Melanie Mitchell, an artificial intelligence expert at the Santa Fe Institute in New Mexico. “We’re beyond the deep learning revolution of the 2010s, and we’re now in the era of generative AI of the 2020s.”
Generative AI systems can produce things that had long seemed safely within the province of human creative ability. AI systems can now answer questions with seemingly human linguistic skill and knowledge, write poems and articles and legal briefs, produce publication quality artwork, and even create videos on demand of all sorts of things you might want to describe.
Many of these abilities stem from the development of large language models, abbreviated as LLMs, such as ChatGPT and other similar models. They are large because they are trained on huge amounts of data — essentially, everything on the internet, including digitized copies of countless printed books. Large can also refer to the large number of different kinds of things they can “learn” in their reading — not just words but also word stems, phrases, symbols and mathematical equations.
By identifying patterns in how such linguistic molecules are combined, LLMs can predict in what order words should be assembled to compose sentences or respond to a query. Basically, an LLM calculates probabilities of what word should follow another, something critics have derided as “autocorrect on steroids.”
Even so, LLMs have displayed remarkable abilities — such as composing texts in the style of any given author, solving riddles and deciphering from context whether “bill” refers to an invoice, proposed legislation or a duck.
“These things seem really smart,” Mitchell said this month in Denver at the annual meeting of the American Association for the Advancement of Science.
LLMs’ arrival has induced a techworld version of mass hysteria among some experts in the field who are concerned that run amok, LLMs could raise human unemployment, destroy civilization and put magazine columnists out of business. Yet other experts argue that such fears are overblown, at least for now.
At the heart of the debate is whether LLMs actually understand what they are saying and doing, rather than just seeming to. Some researchers have suggested that LLMs do understand, can reason like people (big deal) or even attain a form of consciousness. But Mitchell and others insist that LLMs do not (yet) really understand the world (at least not in any sort of sense that corresponds to human understanding).
“What’s really remarkable about people, I think, is that we can abstract our concepts to new situations via analogy and metaphor.”
Melanie Mitchell
In a new paper posted online at arXiv.org, Mitchell and coauthor Martha Lewis of the University of Bristol in England show that LLMs still do not match humans in the ability to adapt a skill to new circumstances. Consider this letter-string problem: You start with abcd and the next string is abce. If you start with ijkl, what string should come next?
Humans almost always say the second string should end with m. And so do LLMs. They have, after all, been well trained on the English alphabet.
But suppose you pose the problem with a different “counterfactual” alphabet, perhaps the same letters in a different order, such as a u c d e f g h i j k l m n o p q r s t b v w x y z. Or use symbols instead of letters. Humans are still very good at solving letter-string problems. But LLMs usually fail. They are not able to generalize the concepts used on an alphabet they know to another alphabet.
“While humans exhibit high performance on both the original and counterfactual problems, the performance of all GPT models we tested degrades on the counterfactual versions,” Mitchell and Lewis report in their paper.
Other similar tasks also show that LLMs do not possess the ability to perform accurately in situations not encountered in their training. And therefore, Mitchell insists, they do not exhibit what humans would regard as “understanding” of the world.
“Being reliable and doing the right thing in a new situation is, in my mind, the core of what understanding actually means,” Mitchell said at the AAAS meeting.
Human understanding, she says, is based on “concepts” — basically mental models of things like categories, situations and events. Concepts allow people to infer cause and effect and to predict the probable results of different actions — even in circumstances not previously encountered.
“What’s really remarkable about people, I think, is that we can abstract our concepts to new situations via analogy and metaphor,” Mitchell said.
She does not deny that AI might someday reach a similar level of intelligent understanding. But machine understanding may turn out to be different from human understanding. Nobody knows what sort of technology might achieve that understanding and what the nature of such understanding might be.
If it does turn out to be anything like human understanding, it will probably not be based on LLMs.
After all, LLMs learn in the opposite direction from humans. LLMs start out learning language and attempt to abstract concepts. Human babies learn concepts first, and only later acquire the language to describe them.
So LLMs are doing it backward. In other words, perhaps reading the internet might not be the correct strategy for acquiring intelligence, artificial or otherwise.
In the mountains of southern Spain, one type of thistle plant seems to have built-in air conditioning.
The flowers of the thistle Carlina corymbosa are, on average, about 3 degrees Celsius cooler than the surrounding air, ecologist Carlos Herrera reports February 13 in Ecology. The most extreme cooling — sometimes up to 10 degrees C — occurs during the hottest part of the day. This means when the air temperature reaches a sweltering 45° C, the plant’s flowers can remain close to a relatively cool 35° C.
“Those are substantial coolings relative to the air next to it,” says Christopher Still, an ecologist at Oregon State University in Corvallis who was not involved in the work. “It’s a nice, careful study.”
In Spain’s Sierra de Cazorla mountain range, scorching summers leave many plants dead, dried out or dormant. This brown sea is intermittently broken by bursts of yellow, as C. corymbosa improbably peeks its flowers above the vegetation. When Herrera, of the Spanish National Research Council in Sevilla, touched one of the flower heads during the peak of the day’s heat on a recent trek, he found it pleasantly cool.
Herrera was there to study the relationship between the region’s plants and their pollinators. He bent to touch the thistle because he “was checking for the presence of nectar in the flower head,” he says, and then became curious about why the flower felt chilled.
Using an electric thermometer, he measured the temperatures of seven different thistles across two sites and multiple days per flower. He found the flowers consistently cooled down as the day grew hotter.
Many plants cool down by passively allowing water to evaporate through pores, a process called transpiration that is analogous to humans beating the heat by sweating (SN: 2/27/06). Most research has focused on how leaves keep cool, but in many cases, leaves don’t get colder than the surrounding air. When they do, Herrera reports, the difference in temperature is less drastic than seen in the thistle flowers.
There’s probably some truth to the idea that the thistle cools itself down more than leaves, but because flowers and leaves are measured differently, it’s hard to say for sure, Still says.
Because the thistles started cooling down at the hottest part of the day, it’s possible that the plants are actively turning a self-refrigerating mechanism on and off.
The idea that plants might be controlling their internal temperatures took off in the late 1980s, and is known as “limited homeothermy.” However, this is a rare skill among plants, Still says. A 2022 study he led found no evidence that leaves in forest canopies across North and Central America were cooler than the air around them.
Both Herrera and Still think that something about the thistle flower’s shape and structure enables it to cool off so effectively.
Herrera suspects that as water within the thistle evaporates, it takes heat with it, and because of the flower’s physical form, that heat isn’t being replaced by the sun’s warmth. This might allow the plant to cool below the air temperature. Herrera dubs this the “botijo effect,” because “it is the same principle by which porous sweating pitchers” — called botijos in Spanish — “cool themselves in dry, hot air.” This idea needs to be tested, however.
Herrera and Still are both curious to know if being cooler than the surrounding air provides any benefit to the thistle, such as by attracting pollinators trying to escape the oppressive summer heat. Herrera plans to see if other thistles in southern Spain show the same cooling effect and has also mapped out an experiment to probe how limiting the plant’s access to water may influence its cooling ability.
“There’s a lot of value in old-fashioned naturalism,” Still says. “This one study could lead to lots of cool follow-on work.”
Consider this sequence of numbers: 5, 7, 9. Can you spot the pattern? Here’s another with the same pattern: 15, 19, 23. One more: 232, 235, 238.
“Three equally spaced things,” says Raghu Meka, a computer scientist at UCLA. “That’s probably the simplest pattern you can imagine.”
Yet for almost a century, mathematicians in the field of combinatorics have been puzzling out how to know whether an endless list of numbers contains such a sequence, called an arithmetic progression. In other words, is there a way to be mathematically certain that a set contains a sequence of three or more evenly spaced numbers, even if you don’t know much about how the numbers in the set were selected or what the progression might be?
Progress on the question has been slow, even plodding. But last year, Meka and Zander Kelley, a Ph.D. computer science student at the University of Illinois Urbana-Champaign, surprised mathematicians by making an exponential leap. The researchers are outsiders in combinatorics, which is concerned with counting configurations of numbers, points or other mathematical objects. And the duo didn’t set out to tackle the mystery of arithmetic progressions.
Kelley and Meka were instead investigating abstract games in computer science. The pair sought a mathematical tool that might help them understand the best way to win a particular type of game over and over again. “I’m super-interested in a collection of techniques that fall under this umbrella called structure versus randomness,” Kelley says. Some of the earliest progress on arithmetic progressions relied on such techniques, which is what led Kelley and Meka to dive into the topic.
The mystery of whether arithmetic progressions will show up is just one of many mathematical questions related to order versus disorder in sets of objects. Understanding order — and when and where patterns must emerge — is a recurring theme in many branches of math and computer science.
Another example of order in objects says that any group of six people must contain either a group of at least three mutual acquaintances (all three know each other) or a group of at least three complete strangers (no one knows another). Research has shown that it doesn’t matter who they are, where they are from or how they were selected. There’s something powerful, maybe almost spooky, about the fact that we can say this — and make other similar claims about structure in sets — with mathematical certainty.
Solving the mystery of arithmetic progressions might open doors to investigating more complex relationships among numbers in a set — gaps that change in more elaborate ways, for instance. “These are more sophisticated versions of the same theorems,” says Bryna Kra, a mathematician at Northwestern University in Evanston, Ill. “Typically, once you see arithmetic progressions … you see other patterns.”
After publishing their work on arithmetic progressions, Kelley and Meka, with Shachar Lovett of the University of California, San Diego, imported techniques from their investigations of arithmetic progressions into a different context. The researchers solved a question in communication complexity, a subfield of theoretical computer science concerned with transmitting data efficiently between parties who have only partial information.
What’s more, knowing that certain mathematical structures have to appear in certain situations can be useful in real-world communication networks and for image compression.
Potential applications aside, researchers who study arithmetic progressions — or other facets of purely theoretical mathematics — are often motivated more by sheer curiosity than any practical payoff. The fact that questions about such simple patterns and when they appear remain largely unanswered is, for many, reason enough to pursue them.
What are arithmetic progressions?
Let’s take a moment to get our hands on some sets of numbers and the arithmetic progressions those sets contain, starting with the prime numbers, perennial favorites of math enthusiasts. A prime number is any whole number divisible only by itself and by 1; the first 10 primes are 2, 3, 5, 7, 11, 13, 17, 19, 23 and 29. Within those numbers, we can find a few arithmetic progressions. The numbers 3, 5 and 7 form a three-term arithmetic progression with a gap of two. But the numbers in a progression don’t have to follow each other immediately within the larger set: The numbers 5, 11, 17, 23 and 29 form a five-term arithmetic progression with a gap of six.
Within a finite set of numbers, it’s straightforward to determine whether there are any arithmetic progressions. It might be tedious depending on the set, but it’s not mysterious. For infinite sets of numbers, though, the question gets interesting.
The primes go on forever, and mathematicians have asked many — and answered some — questions about arithmetic progressions within them. Is there a longest possible arithmetic progression, a cap on the number of terms, in the primes? Or, can you find a progression of any finite length if you look long enough? In 2004, mathematicians proved that the latter is true. But questions including how far along the number line you have to look to find an arithmetic progression with a given number of terms or a given gap size remain active areas of research, for the primes and for other sets.
A simple arithmetic progression
It’s easy to create an arithmetic progression, a sequence of numbers that are equally spaced. Just start with any number and add the same number repeatedly (the number 2, in this example). Creating a set of numbers that avoids arithmetic progressions can be harder though.C. Chang
The primes contain infinitely many arithmetic progressions, but some infinite sets contain none. Consider the powers of 10: 1, 10, 100, 1,000…. The gaps between consecutive terms get bigger fast — 9, 90, 900…. And none of them are the same. Playing around with the numbers a bit, you can convince yourself that no two powers of 10, whether consecutive or not, have the same gap as any other pair.
With that context, we now approach a question at the heart of this research: Why do some sets have arithmetic progressions while others don’t? One big difference between the primes and powers of 10 is that there are a lot more primes than powers of 10. Sort of. Both sets are infinite, but if you pick any arbitrary number as a cutoff and look at how many primes or powers of 10 there are below that number, the primes win every time. There are four primes from 1 to 10, versus only two powers of 10. There are 25 primes from 1 to 100 and only three powers of 10. The primes don’t just win every time, they win by a lot, and the amount they win by keeps increasing. In this way, the primes are “denser” — in an intuitive and technical sense — than the powers of 10.
A sparse enough set of numbers can have gaps arranged in ways that manage to avoid arithmetic progressions. Too dense, though, and the set can’t avoid having gaps that match up. In the 20th century, mathematicians settled on a way to measure that density. They are now looking for the density above which arithmetic progressions must appear.
Density in infinite sets
The study of arithmetic progressions in sets of whole numbers began in earnest in 1936, when Hungarian mathematicians Paul Erdős and Pál Turán posited that any set of whole numbers that is dense enough must contain arithmetic progressions of any desired length.
For finite sets, it’s easy to understand what density is. In the set of whole numbers between 1 and 10, the primes have a density of 4/10, or 0.4. But if we want to understand the density of the entire unending collection of prime numbers within the entire unending collection of the whole numbers, we need to find a way to make sense of infinity divided by infinity, or ∞/∞.
In the 1930s, Hungarian mathematicians Paul Erdős (left) and Pál Turán (right) proposed that any set of numbers that is dense enough must contain an arithmetic progression.FROM LEFT: KMHKMH/WIKIMEDIA COMMONS (CC BY 3.0); BUNDESARCHIV, BILD 183-33149-0001/WIKIMEDIA COMMONS (CC BY-SA 3.0)
Mathematicians use a concept called asymptotic density to wrangle with the density of an infinite set of whole numbers. The basic idea is to choose some number as a cutoff point, N, and see what happens as N increases. If the density tends toward some fixed number, that is the set’s asymptotic density.
Let’s return to the powers of 10, whose density decreases across the number line. As you go out farther and farther, the proportion of whole numbers that are powers of 10 approaches zero — so the set has an asymptotic density of zero. Other sets have a positive asymptotic density, and some never settle down into an asymptotic density at all.
What Erdős and Turán proposed is that any set of numbers with positive, rather than zero, asymptotic density must contain at least one arithmetic progression. For some sets, it’s obvious (the even numbers have an asymptotic density of 0.5 and definitely contain arithmetic progressions). But proving it for any arbitrary set of numbers turned out to be a challenge.
It wasn’t until 1953 that German-British mathematician Klaus Roth proved the conjecture, opening the door to a more nuanced understanding of the role density plays in arithmetic progressions. He showed that any set with positive asymptotic density must contain at least one three-term arithmetic progression, or 3-AP. His argument relied on proving that dense enough pseudorandom sets — those that might not truly be chosen randomly but have the general properties of random sets — must contain arithmetic progressions. Then he developed a way to zoom in on parts of non-pseudorandom sets and show that, if the initial set is dense enough, these zoomed-in areas must be structured in ways that guarantee the presence of an arithmetic progression.
In early 2021, Kelley and Meka were investigating a problem in complexity theory called parallel repetition of games. Don’t think Monopoly or chess; the “games” the researchers were thinking about won’t be making Hasbro money any time soon. “We have a tendency to call anything a game if it has turns,” says Kelley. In the typical games Kelley and Meka were looking at, the players have access to different information and have to work together to find an answer to a question. But they can’t communicate during the game, so they must decide on a strategy beforehand. Kelley and Meka sought to determine how to maximize the chances that the players win many games in a row.
It’s not quite a hop, skip and a jump from parallel repetition of games to arithmetic progressions, but Kelley and Meka got there fairly quickly. “Maybe in a month we were at the 3-AP problem,” Meka says. Previous research on parallel repetition of games had used structure versus randomness arguments. Because Roth’s work on arithmetic progressions was the first to use such a technique, Kelley and Meka were interested in that work in its original habitat.
“In theoretical computer science, people are looking outward to math for some tools that they could use, and unless you’re ready to get yourself into some serious trouble, usually you see if you can use the tools, and then if you can’t, you move on,” Kelley says. “You don’t try to go open them up and see what they’re like.” But he and Meka did just that, knowing that they might go down a deep rabbit hole and end up with nothing to show for their time and effort. They dug into Roth’s arguments — as well as more recent research on the same subject — to see if they could push the work further. And so they found themselves staring down arithmetic progressions.
To find out more about order among six people, and objects more generally, check out this Numberphile video about friends and strangers.
Reaching new limits
Roth’s contribution was more powerful than just showing that any set with positive asymptotic density must contain a 3-AP. He also proved that some sets with asymptotic density of zero, if the density tends toward zero slowly enough as you go out along the number line, must also contain at least one 3-AP.
Think of the density as having to pass beneath a limbo bar. If a set gets sparse too slowly, it can’t make it under and it must contain an arithmetic progression. But a set that approaches a density of zero quickly enough ducks under. For that set, anything goes: It may or may not have such a progression.
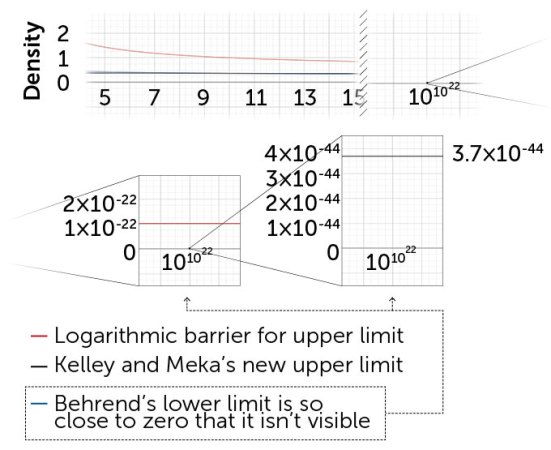
Roth’s initial proof found an upper limit to where the limbo bar must be. He showed that any set whose density approaches zero at a rate similar to or slower than the expression 1/log(log(N)) must contain at least one arithmetic progression. Log means to take the logarithm, and remember that N is the number chosen as the arbitrary cutoff in an infinite set. We’re considering what happens as N increases.
Logarithms grow slowly, roughly akin to the number of digits a number has. The logarithm of 1 is zero, of 10 is 1, of 100 is 2, of 1,000 is 3, and so on. But taking the logarithms of those logarithms gives much more sluggish growth. To nudge log(log(N)) from zero to 1, we have to move N from 10 to 10 billion. Dividing 1 by this double log, as appears in Roth’s work, we get a density that just plods toward zero.
Several years earlier, in 1946, mathematician Felix Behrend had investigated the lower limit of the limbo bar. He developed a recipe for cooking up sets without 3-APs, showing that any such set must be extremely sparse indeed. His limit was a density that goes to zero at approximately the same rate as 1/e(log(N))^½. That expression might not look familiar, but there’s an exponential function in the denominator. The log and ½ power slow things down a bit, but the whole expression goes to zero much faster than the double log Roth later found.
In the last few decades, researchers have been attempting to close the gap between Roth-style estimates of the sparsest sets that must contain a 3-AP and Behrend-style estimates of the densest sets that do not contain one. In 2020, mathematicians Thomas Bloom of the University of Oxford and Olof Sisask of Stockholm University broke what had come to be known as the logarithmic barrier for the Roth-style upper limit of the limbo bar, showing that any set with a density that goes to zero more slowly than 1/log(N) must contain at least one 3-AP. The work was seen as a breakthrough in the field, though the upper limit was still closer to the previous best-known upper limit than to Behrend’s lower limit.
Kelley and Meka pushed the upper limit down dramatically. Their result was a rate that goes to zero at approximately the same rate as 1/e(log(N))^1/11. That formula looks eerily similar to Behrend’s lower limit. For the first time ever, the upper and lower limits are within shooting distance of each other. Closing that gap would reveal the specific location of the limbo bar and thus give a clear answer to which sets must contain at least one 3-AP.
Headed to zero
How quickly a set’s density approaches zero as you move far out along the number line (insets) can reveal whether that set must contain an arithmetic progression. In 2023, computer scientists Zander Kelley and Raghu Meka showed that if the density approaches zero at a rate roughly similar to or slower than the black line above, the set must contain a progression. This upper limit is dramatically lower than “the logarithmic barrier” (broken in 2020 and shown in red), but it is still a long way from the lower limit (identified by Felix Behrend decades ago).
Upper and lower limits for sets that contain an arithmetic progression
E. LAMB, C. CHANGE. LAMB, C. CHANG
What’s next?
When Kelley and Meka started on the 3-AP problem, they thought they would probably just poke around to identify the barriers to moving the upper limit down. A year later, the two were writing a paper about their breakthrough. “I think one thing that kept us going was it never felt like we were completely hitting a wall,” Meka says. “It always felt like we were either learning something useful, or we were actually making progress.”
Meka describes their overall approach, based on Roth’s early techniques, as exploiting a “wishful dichotomy” between randomness and structure. They developed a definition of pseudorandomness for their work and showed that for this definition, any dense enough pseudorandom set must contain at least one arithmetic progression.
After handling the pseudorandom case, the team considered more structured sets of numbers and showed that those sets too had to exhibit the desired patterns. Finally, Kelley and Meka expanded from these types of sets to all large enough sets of numbers, proving that those sets must have the properties of either the pseudorandom or the structured sets.
“Three equally spaced things. That’s probably the simplest pattern you can imagine.”
Raghu Meka
The most remarkable thing about Kelley and Meka’s work is that they were able to make such dramatic progress without developing a new approach to arithmetic progressions. Though they brought new insights and established new connections to previous work, they did not create new machinery.
“It just seemed completely intractable to push those techniques through,” Sisask says, “until this paper by Kelley and Meka landed in my inbox.” He and Bloom, who had previously broken the logarithmic barrier, “spent a while digesting the paper and talking about it until we understood it in our own language,” he says.
Mathematicians and computer scientists tend to use some different notation and terminology, but Sisask, Bloom and other experts in the field quickly recognized the work as solid. After digesting the arguments, Sisask and Bloom wrote an explanation of the work, with some subtle technical improvements, geared toward other researchers in combinatorics. Several months later, the team coaxed the upper limit down a tiny bit more, getting a new bound of 1/e(log(N))^1/9.
Combinatorics researchers are still trying to figure out how low they can go. Will they be able to push the upper limit all the way down to the best known lower limit, or will there always be a little gap where our knowledge is incomplete? Kelley and Meka are using the tools they honed on arithmetic progressions to continue work on problems in complexity theory and other areas of theoretical computer science.
When I asked Meka how two computer scientists made such a big advance on a mathematics problem that had stumped combinatorics experts for years, he said he isn’t sure. He thinks maybe their edge came from being fresh to the challenge.
“The problem has been around for a long time and progress seemed pretty stuck,” he says. In fact, after he and Kelley were well on their way to publishing, Kelley says he ran across a blog post from 2011 that outlined exactly why mathematicians were pessimistic about the very approach that the two had eventually used.
“People thought that these techniques couldn’t push beyond existing barriers,” Meka says, “but maybe we didn’t know that the barriers existed.”
Earth’s oldest, knotted and scarred pine trees are a boon for forest life.
These old mountain pines (Pinus uncinata) offer food and shelter for lichens and insects not just because they’re old, but also because of what’s allowed them to grow so old in the first place, researchers report February 5 in the Proceedings of the National Academy of Sciences. The findings highlight the broader importance of big, old trees, and suggest threats to their survival from development, fire or climate change could deliver irreparable harm in certain ecosystems.
Old growth trees continue to decline around the world (SN: 6/18/18). In Europe, the remaining patches of forest with plentiful old trees constitute just 0.7 percent (or just under 3.5 million acres) of the continent’s forested area. This paper and others like it “are really good, because they show how important old growth is,” says Joseph Birch, an ecologist at Michigan State University in East Lansing who wasn’t involved with the research. This line of work serves as a reminder that we need to have a long-term perspective on old growth trees. “We need to be managing and conserving the forests that we have now, even if they’re younger, so that our descendants in a few hundred or even thousand years can have more old growth on the landscape,” Birch says.
Ancient mountain pines grow twisted and crooked over their hundreds of years of growth. Dead and decaying parts of the plant, as shown in this tree in Aigüestortes i Estany de Sant Maurici National Park in Catalonia, can serve as habitats for multiple forest species. Ot Pasques
While the pines’ old age, potentially hundreds of years old, was intriguing to plant physiologist Sergi Munné-Bosch and ecophysiologist Ot Pasques, both at the University of Barcelona, they have also been curious how aging and tree decay affect the broader forest ecosystem, with different life and decay stages providing differing habitat needs to plant, animal and lichen species.
Prior studies tended to look at how individual trees aged. So Munné-Bosch and Pasques decided up the ante. They studied young, adult and extremely old mountain pines in five different areas of the Spanish Pyrenees mountains. The duo calculated the trees’ ages based on tree trunk girth. (The two traits are correlated, eliminating the need to bore a sample out of the trunk to count tree rings). The team also weighed and measured needles, buds and shoots, analyzed the trees’ tissues for biochemicals linked to stress, decay and growth and noted age-related physical traits in the trees — such as exposed roots, fissured bark and lightning scars. Data on other species living in or on the trees were also recorded.
The results show that the oldest trees no longer spend a lot of energy on reproduction, ramping down the production of cones and buds, slowing their growth considerably and prioritizing stress tolerance and long-term durability. Ancient trees also allow parts of their bodies to die and decay alongside living sections. These are adaptations for staying alive hundreds of years, and they make the oldest trees knotted, scarred and full of large, dead sections, which are exploited by other forest life.
Ant colonies and plants like mountain houseleek (Sempervivum montanum) live in these dead and decaying sections. Trees with biochemical changes associated with decline and decay also tended to host more lichen, and the bigger, older trees had a higher diversity of lichen living on them. “Lichens look for very specific microhabitats for survival in high mountains,” Munné-Bosch says. Wolf lichen (Letharia vulpina), for instance, is rare in this part of Europe, and when the team encountered it, it was growing mostly on ancient pines.
Lichens grow on the gnarled branches of an ancient mountain pine in Alt Pirineu Natural Park, located high in the Spanish Pyrenees.Ot Pasques
Younger pines, which don’t have the unique physical and physiological features of ancient trees, can’t support forest life like ancient trees do. This makes ancient trees’ ecological role “irreplaceable,” Munné-Bosch says.
“For a lot of people who work with old trees, this is something that we intuitively knew. But it hadn’t necessarily been presented in this way and with such a compelling body of evidence to support it,” Birch says.
These results are only for a single tree species, he notes. In giant sequoias, which live thousands of years, aging doesn’t cause the tree to contort in shape as dramatically as the stunted mountain pines that grow at high elevations, so ancient sequoias’ influence on biodiversity might look different.
Branching out to study other tree species is the team’s next step, Munné-Bosch says.
In January, Mark Zuckerberg, CEO of Facebook’s parent company Meta, appeared at a congressional hearing to answer questions about how social media potentially harms children. Zuckerberg opened by saying: “The existing body of scientific work has not shown a causal link between using social media and young people having worse mental health.”
But many social scientists would disagree with that statement. In recent years, studies have started to show a causal link between teen social media use and reduced well-being or mood disorders, chiefly depression and anxiety.
Ironically, one of the most cited studies into this link focused on Facebook.
Researchers delved into whether the platform’s introduction across college campuses in the mid 2000s increased symptoms associated with depression and anxiety. The answer was a clear yes, says MIT economist Alexey Makarin, a coauthor of the study, which appeared in the November 2022 American Economic Review. “There is still a lot to be explored,” Makarin says, but “[to say] there is no causal evidence that social media causes mental health issues, to that I definitely object.”
The concern, and the studies, come from statistics showing that social media use in teens ages 13 to 17 is now almost ubiquitous. Two-thirds of teens report using TikTok, and some 60 percent of teens report using Instagram or Snapchat, a 2022 survey found. (Only 30 percent said they used Facebook.) Another survey showed that girls, on average, allot roughly 3.4 hours per day to TikTok, Instagram and Facebook, compared with roughly 2.1 hours among boys. At the same time, more teens are showing signs of depression than ever, especially girls (SN: 6/30/23).
As more studies show a strong link between these phenomena, some researchers are starting to shift their attention to possible mechanisms. Why does social media use seem to trigger mental health problems? Why are those effects unevenly distributed among different groups, such as girls or young adults? And can the positives of social media be teased out from the negatives to provide more targeted guidance to teens, their caregivers and policymakers?
“You can’t design good public policy if you don’t know why things are happening,” says Scott Cunningham, an economist at Baylor University in Waco, Texas.
Increasing rigor
Concerns over the effects of social media use in children have been circulating for years, resulting in a massive body of scientific literature. But those mostly correlational studies could not show if teen social media use was harming mental health or if teens with mental health problems were using more social media.
Moreover, the findings from such studies were often inconclusive, or the effects on mental health so small as to be inconsequential. In one study that received considerable media attention, psychologists Amy Orben and Andrew Przybylski combined data from three surveys to see if they could find a link between technology use, including social media, and reduced well-being. The duo gauged the well-being of over 355,000 teenagers by focusing on questions around depression, suicidal thinking and self-esteem.
Digital technology use was associated with a slight decrease in adolescent well-being, Orben, now of the University of Cambridge, and Przybylski, of the University of Oxford, reported in 2019 in Nature Human Behaviour. But the duo downplayed that finding, noting that researchers have observed similar drops in adolescent well-being associated with drinking milk, going to the movies or eating potatoes.
Holes have begun to appear in that narrative thanks to newer, more rigorous studies.
In one longitudinal study, researchers — including Orben and Przybylski — used survey data on social media use and well-being from over 17,400 teens and young adults to look at how individuals’ responses to a question gauging life satisfaction changed between 2011 and 2018. And they dug into how the responses varied by gender, age and time spent on social media.
Social media use was associated with a drop in well-being among teens during certain developmental periods, chiefly puberty and young adulthood, the team reported in 2022 in Nature Communications. That translated to lower well-being scores around ages 11 to 13 for girls and ages 14 to 15 for boys. Both groups also reported a drop in well-being around age 19. Moreover, among the older teens, the team found evidence for the Goldilocks Hypothesis: the idea that both too much and too little time spent on social media can harm mental health.
“There’s hardly any effect if you look over everybody. But if you look at specific age groups, at particularly what [Orben] calls ‘windows of sensitivity’ … you see these clear effects,” says L.J. Shrum, a consumer psychologist at HEC Paris who was not involved with this research. His review of studies related to teen social media use and mental health is forthcoming in the Journal of the Association for Consumer Research.
Cause and effect
That longitudinal study hints at causation, researchers say. But one of the clearest ways to pin down cause and effect is through natural or quasi-experiments. For these in-the-wild experiments, researchers must identify situations where the rollout of a societal “treatment” is staggered across space and time. They can then compare outcomes among members of the group who received the treatment to those still in the queue — the control group.
That was the approach Makarin and his team used in their study of Facebook. The researchers homed in on the staggered rollout of Facebook across 775 college campuses from 2004 to 2006. They combined that rollout data with student responses to the National College Health Assessment, a widely used survey of college students’ mental and physical health.
The team then sought to understand if those survey questions captured diagnosable mental health problems. Specifically, they had roughly 500 undergraduate students respond to questions both in the National College Health Assessment and in validated screening tools for depression and anxiety. They found that mental health scores on the assessment predicted scores on the screenings. That suggested that a drop in well-being on the college survey was a good proxy for a corresponding increase in diagnosable mental health disorders.
Compared with campuses that had not yet gained access to Facebook, college campuses with Facebook experienced a 2 percentage point increase in the number of students who met the diagnostic criteria for anxiety or depression, the team found.
When it comes to showing a causal link between social media use in teens and worse mental health, “that study really is the crown jewel right now,” says Cunningham, who was not involved in that research.
A need for nuance
The social media landscape today is vastly different than the landscape of 20 years ago. Facebook is now optimized for maximum addiction, Shrum says, and other newer platforms, such as Snapchat, Instagram and TikTok, have since copied and built on those features. Paired with the ubiquity of social media in general, the negative effects on mental health may well be larger now.
Moreover, social media research tends to focus on young adults — an easier cohort to study than minors. That needs to change, Cunningham says. “Most of us are worried about our high school kids and younger.”
And so, researchers must pivot accordingly. Crucially, simple comparisons of social media users and nonusers no longer make sense. As Orben and Przybylski’s 2022 work suggested, a teen not on social media might well feel worse than one who briefly logs on.
Researchers must also dig into why, and under what circumstances, social media use can harm mental health, Cunningham says. Explanations for this link abound. For instance, social media is thought to crowd out other activities or increase people’s likelihood of comparing themselves unfavorably with others. But big data studies, with their reliance on existing surveys and statistical analyses, cannot address those deeper questions. “These kinds of papers, there’s nothing you can really ask … to find these plausible mechanisms,” Cunningham says.
One ongoing effort to understand social media use from this more nuanced vantage point is the SMART Schools project out of the University of Birmingham in England. Pedagogical expert Victoria Goodyear and her team are comparing mental and physical health outcomes among children who attend schools that have restricted cell phone use to those attending schools without such a policy. The researchers described the protocol of that study of 30 schools and over 1,000 students in the July BMJ Open.
Goodyear and colleagues are also combining that natural experiment with qualitative research. They met with 36 five-person focus groups each consisting of all students, all parents or all educators at six of those schools. The team hopes to learn how students use their phones during the day, how usage practices make students feel, and what the various parties think of restrictions on cell phone use during the school day.
Talking to teens and those in their orbit is the best way to get at the mechanisms by which social media influences well-being — for better or worse, Goodyear says. Moving beyond big data to this more personal approach, however, takes considerable time and effort. “Social media has increased in pace and momentum very, very quickly,” she says. “And research takes a long time to catch up with that process.”
Until that catch-up occurs, though, researchers cannot dole out much advice. “What guidance could we provide to young people, parents and schools to help maintain the positives of social media use?” Goodyear asks. “There’s not concrete evidence yet.”
DENVER — A weight-loss drug used to treat obesity and diabetes has shown promise to treat another disorder: opioid addiction.
Early results from a small clinical trial, presented February 17 at the annual meeting of the American Association for the Advancement of Science, suggest that a close relative of the weight-loss drugs Wegovy and Ozempic significantly lessened cravings for opioids in people with opioid use disorder.
“For them to have any time when they might be free of that craving seems to be very hopeful,” Patricia “Sue” Grigson, a behavioral neuroscientist at Penn State College of Medicine in Hershey said at the conference. The vast majority of drug overdose deaths in the United States are due to opioids (SN: 2/14/24).
The drug, called liraglutide, mimics a hormone called GLP-1 that the body releases after people eat. Wegovy and Ozempic — brand names for semaglutide, a molecule that induces weight loss more effectively than liraglutide — also imitate the hormone.
It’s unclear exactly how the drugs work when it comes to weight loss, but researchers think such GLP-1 dupes prompt the body and brain to make people feel full (SN: 12/13/23).
There are hints that such drugs could work for addiction, too. People taking Wegovy or Ozempic have reported lessened desire for not just food but also alcohol and nicotine. What’s more, Grigson and colleagues showed in a previous study in rats that liraglutide can cut down on heroin-seeking behavior, perhaps by changing the animals’ brain activity (SN: 8/30/23).
To test whether liraglutide might work in people as a treatment for opioid addiction, Grigson and colleagues gave the drug to volunteers being treated for opioid use disorder at the Caron Treatment Center in Wernersville, Pa. The team analyzed data from 20 people, 10 of whom were slated to receive increasing drug doses over 19 days. The remaining 10 people received a placebo.
At higher doses of liraglutide, patients dropped out of the trial largely due to gastrointestinal symptoms including nausea, a known side effect of these drugs. Still, the treatment began reducing opioid cravings at the lowest dose, Grigson said, and desire for opioids was reduced by 30 percent overall.
That’s equivalent to the effect of about 14 days of intensive treatment at a residential center, Grigson said.
The results need to be confirmed in larger trials, she said. The team also hopes to try out other GLP-1 drugs, which may be more effective and come with fewer side effects, and include people with different levels of addiction.
Many if not most of the articles in Science News involve some math, whether as an essential tool in conducting research or a way to solve real-world problems, such as how to calculate a safer crowd size during the pandemic, detect gerrymandering in voter districts or cook the perfect steak.
But sometimes we dig into pure mathematics — math that doesn’t address an immediate practical need but is worthy of pursuit for its own sake. That includes last year’s discovery of an “einstein” tile, a long-sought two-dimensional shape that can cover an infinite surface but only with a pattern that never repeats (SN: 4/22/23, p. 7).
In this issue, we report on a big advance in combinatorics, which is about as pure mathy as a topic can be (we also revisit the einstein tile). The tale centers on two computer scientists. While trying to solve a seemingly unrelated problem in a distant field, the pair made a breakthrough in a puzzle that mathematicians have been wrestling with for a century.
Combinatorics is a branch of mathematics that involves the counting and arrangement of numbers or other things. An enduring question in combinatorics is whether it’s possible to predict whether an infinitely long list of numbers must include an arithmetic progression: a sequence of equally spaced numbers such as 2, 5, 8, 11, 14, 17.
On first glance, this doesn’t sound like the kind of challenge that brilliant people would devote decades of their lives to figuring out. But as freelance writer Evelyn Lamb, a mathematician herself, explains, people seem hardwired to seek out puzzles and driven to find the answers. “We humans just love going down these rabbit holes, having natural curiosity and building theories about things we see around us,” Lamb told me. “We all have things we’re super-interested in and then start diving deep.”
Arithmetic progressions have fascinated people since antiquity. Today, these sequences and other repeating patterns are part of many areas of math and computer science, providing both challenges and potential solutions. Such patterns can also provide a bit of fun. You don’t have to be a mathematician to get hooked on the plethora of sequence puzzles, whether based on numbers, letters or symbols, that are all over the internet.
I confess that I’m not someone who would put “learn more about combinatorics” at the top of my to-do list. But I was quickly drawn into the tale Lamb tells. Part of the appeal, she says, is that most everyone was introduced to numbers at a very young age, and many of us have played around with arithmetic progressions in school or in games, even if we’ve never heard the term. It’s not hard to become intrigued with something that seems so simple but can quickly become so complicated.
But if numbers can feel almost innate, they can also be intimidating. “If you feel bad at math, you feel like you’re not smart,” Lamb says. Her goal in telling the story of people’s long-held fascination with arithmetic progressions is to help us enjoy math for math’s sake. Read her article, and I think you will.
Researchers may have gotten to the root of tea’s soothing effect.
The quality of a cup of chai can be enriched by modifying the microbial community that populates the plant’s roots, researchers report February 15 in Current Biology. The secret is to inoculate roots with bacteria that boost the synthesis of the amino acid theanine.
There’s something in tea that helps us wind down, says Zhenbiao Yang, a plant cell biologist at the Shenzhen Institute of Advanced Technology in China. Some studies suggest that the “chemical that helps you sleep is theanine,” he says. What’s more, theanine infuses tea with umami, a taste often described a savoriness, he says.
Yang and colleagues analyzed the microbial communities inhabiting the roots of two oolong tea plant varieties: a sweet, low-theanine cultivar called maoxie and a cinnamony, high-theanine variety called rougui. On the rougui roots, they found more microbes that metabolize nitrogen, a nutrient tea plants convert into theanine.
The researchers then isolated 21 bacterial strains from rougui roots to concoct an experimental microbial medley, which they called SynCom. They disinfected the roots of seedlings of several tea plant varieties, grew them in sterilized vermiculite soil for a few weeks, and then inoculated soils with live or dead SynCom. They also added a nutrient solution that was either low or high in nitrogen.
After 20 days, Yang’s team found that the addition of live SynCom boosted theanine levels in each of the varieties. The effect was especially pronounced under the lower nitrogen conditions — leaves of maoxie plants inoculated with living SynCom contained almost 0.007 milligrams per gram of theanine, 0.005 mg/g higher than maoxie inoculated with dead SynCom.
The next step will be to refine SynCom to facilitate its production and distribution, Yang says. “If we have only like one or two [strains], it will be really easy.”
Foodies of the future may be dining on beefed-up rice.
A new lab-grown meat product merges rice grains with cow cells, scientists report February 14 in Matter. The rice acts as a scaffold that supports the growth of fat or muscle cells. Together, the ingredients form a rice-meat hybrid that steams up to a pinkish-brown mash.
It tasted delicious, “nutty and a little sweet,” says Sohyeon Park, a chemical engineer at Yonsei University in Seoul, South Korea. Lab-made beefy rice isn’t ready for the dinner table yet, she says, but it could one day offer a more sustainable way to eat meat.
Current methods for producing meat include farming cattle, which requires vast expanses of pastureland and emits more than 100 million metric tons of methane into the atmosphere each year. Finding ways to eschew the moo may be better for the environment, scientists suggest. Some potential alternatives include cricket farming and swapping meat for fermented fungal spores (SN: 5/2/19; SN: 5/5/22).
Lab-grown meat is another way to cut the cow (mostly) out of the equation. In the lab, Park and colleagues coated rice grains with fish gelatin and enzymes and then added cow cells to each grain. The fishy coating helped the cells stick to and grow inside the grains. And rice offers a 3-D structure for cells to cling to, like vines climbing a trellis. That structure gives the cultured cells a more meatlike heft, Park says. On their own, the cells grow in thin, flat layers.
Nutritionally, the hybrid rice is more sizzle than steak, with just 8 percent more protein than conventional rice. But Park hopes to boost that number by packing more cow cells into each grain. Rice wasn’t originally on her radar; but the grains worked surprisingly well, she says. What’s more, they’re inexpensive, nutritious and already popular — a grade-A ingredient.